


Specialized LLMs: ChatGPT, LaMDA, Galactica, Codex, Sparrow, and More
Simple techniques for creating better, domain-specific LLMs...


This newsletter is supported by Alegion. At Alegion, I work on a range of problems from online learning to diffusion models. Feel free to check out our data annotation platform or contact me about potential collaboration/opportunities!
If you like this newsletter, please subscribe, share it, or follow me on twitter. Thank you for your support!

Large language models (LLMs) are incredibly-useful, task-agnostic foundation models. But, how much can we actually accomplish with a generic model? These models are adept at solving common natural language benchmarks that we see within the deep learning literature. But, using LLMs practically usually requires that the model be taught new behavior that is relevant to a particular application. Within this overview, we will explore methods of specializing and improving LLMs for a variety of use cases.
We can modify the behavior of LLMs by using techniques like domain-specific pre-training, model alignment, and supervised fine-tuning. These methods can be used to eliminate known limitations of LLMs (e.g., generating incorrect/biased info), modify LLM behavior to better suit our needs, or even inject specialized knowledge into an LLM such that it becomes a domain expert.
The concept of creating specialized LLMs for particular applications has been heavily explored in recent literature. Though many different methodologies exist, they share a common theme: making LLMs more practically viable and useful. Though the definition of “useful” is highly variable across applications and human users, we will see that several techniques exist that can be used to adapt and modify existing, pre-trained LLMs, such that their performance and ease-of-use is drastically improved in a variety of applications.
Background
We have covered the topic of language models (LMs) and large language models (LLMs) in recent, prior posts on this topic. See the references below for each of these overviews:
Language Models: GPT and GPT-2 [blog]
Language Model Scaling Laws and GPT-3 [blog]
Moderns LLMs: MT-NLG, Chinchilla, Gopher, and More [blog]
We will briefly summarize these ideas in this overview. But, we will mostly shift our focus towards applications where basic language modeling alone falls short.
We can only accomplish so much by just teaching a model to predict the next word in a sequence. To elicit particular behavior, we need to adopt new approaches of training language models that are a bit more specific. In addition to being highly-effective at improving language model quality, we will see that these alternative approaches of modifying/fine-tuning language models are pretty cheap compared to pre-training them from scratch.
what are language models?

the basic setup. Most modern language models that we will be talking about utilize a decoder-only transformer architecture [1]. These models are trained to perform a single, simple task: predicting the next word (or token) in a sequence. To teach the model to do this well, we gather a large dataset of unlabeled text from the internet and train the model using a self-supervised language modeling objective. Put simply, this just means that we:
Sample some text from our dataset
Try to predict the next word with our model
Update our model based on the correct next word
If we continually repeat this process with a sufficiently large and diverse dataset, we will end up with a high-quality LM that contains a relatively nuanced and useful understanding of language.
why is this useful? Although LMs are obviously good at generating text, we might be wondering whether they are useful for anything else. What can we actually accomplish by just predicting the most likely next word in a sequence?
Actually, we can solve many different tasks with LMs. This is because their input-output structure (i.e., take text as input, produce text as output) is incredibly generic, and many tasks can be re-formulated to fit this structure via prompting techniques. Consider, for example, the following inputs.
“Identify whether this sentence has a positive or negative sentiment: <sentence>”
“Translate the following sentence from English into French: <sentence>”
“Summarize the following article: <article>”
Using such input prompts, we can take common language understanding tasks and formulate them into an LM-friendly, text-to-text structure—the most likely output from the LM should solve our desired problem. With this approach, we can solve a wide range of problems from multiple choice question answering to document summarization, as is shown by GPT-3 [2].

To improve performance, we can include examples of correct output within our prompt (i.e., a one/few-shot learning approach) or fine-tune the LM to solve a particular task. However, fine-tuning forces the LM to specialize in solving a single task, requiring a separate model to be fine-tuned for each new task; see above.
scaling up. Earlier LMs like GPT and GPT-2 showed a lot of promise [3,4], but their zero/few-shot performance was poor.
However, later research indicated that LM performance should improve smoothly with scale [5]—larger LMs are better! This was confirmed by GPT-3 [2], a 175 billion parameter model (i.e., much bigger than any previous model) that was really good at few-shot learning. The secret to this success was:
Obtaining a big, diverse dataset of unlabeled text
Pre-training a much larger model over this dataset using a language modeling objective
Using prompting to solve tasks via few-shot learning
Using these simple ingredients, we could train large language models (LLMs) that achieved impressive performance across many tasks. These LLMs were powerful, task-agnostic foundation models.
Given that larger LLMs perform well, later work explored even larger models. The results (arguably) weren’t groundbreaking. But, if we combine larger models with better pre-training datasets, LLM quality improves quite a bit! By obtaining much better pre-training corpora (e.g., Massive Text) and pre-training LLMs over more data, we could obtain models like Chinchilla that are both smaller and more performance relative to GPT-3.
where do generic LLMs fall short?
This generic paradigm for pre-training LLMs and using them to solve a variety of problems downstream is great. But, we run into problems when trying to accomplish something more specific than general linguistic understanding. For the purposes of this post, we will focus on two main areas where this desire for more specialized LLM behavior arises:
Alignment
Domain Specialization

alignment. Oftentimes, a generic LLM will generate output that is undesirable to a human that is interacting with the model. For example, we might want to:
Prevent our LLM from being racist
Teach the model to follow and execute human directions
Avoid the generation of factually incorrect output
In other words, we might want to align the LLM to the particular goals or values of humans who are using the model; see above.
After powerful LLM foundation models like GPT-3 were created, the focus of LLM research quickly pivoted towards a focus on this problem of alignment. Although a bit vague to describe (i.e., how do we define the rules to which we align LLM behavior?), the idea of alignment is quite powerful. We can simply teach our LLM to behave in a way that is more safe and useful for us as humans.
The language modeling objective used for many recent large LMs—predicting the next token on a webpage from the internet—is different from the objective “follow the user’s instructions helpfully and safely” - from [6]
domain-specific models. Beyond alignment, we can consider the deployment of LLMs in specialized domains. A generic LLM like GPT-3 cannot successfully generate legal documents or summarize medical information—specialized domains like law or medicine contain lots of complex domain knowledge that is not present within a generic pre-training corpus. For such an application, we need to somehow create an LLM that has a deeper knowledge of the particular domain in which we are interested.
refining LLM behavior
Given that we might want to align our LLM to particular goals or enable more specialized behavior, there are probably two major questions that will immediately come to mind:
How do we do this?
How much is it going to cost?
The first question here is a bit more complex to address because there are several viable answers.
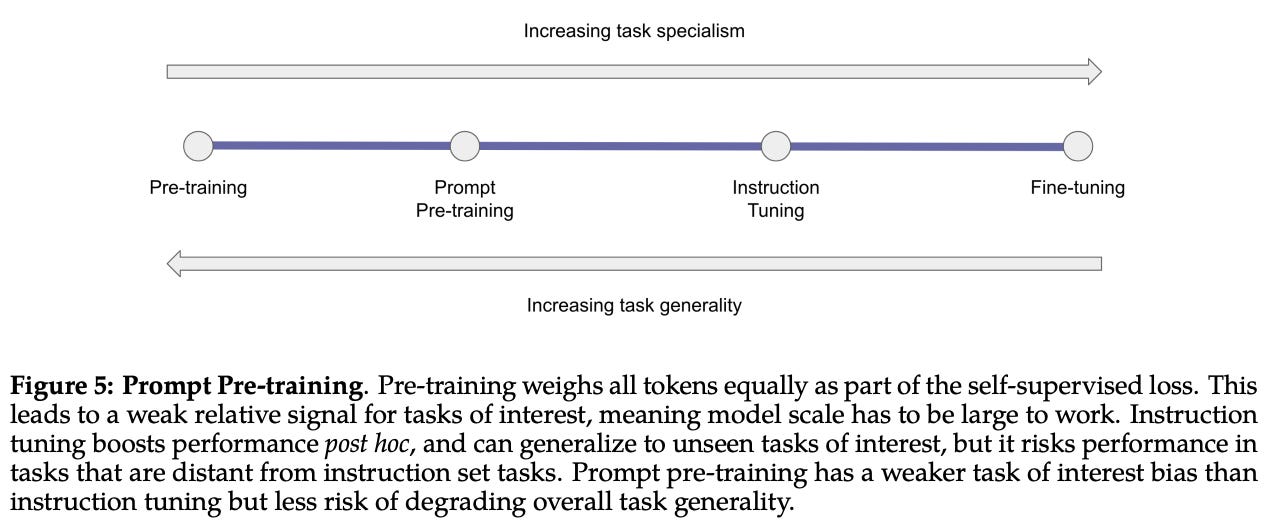
domain-specific pre-training. If we want our LLM to understand a particular area really well, the easiest thing to do would be to (i) collect a lot of raw data pertaining to this domain and (ii) train the model using a language modeling objective over this data. Such a process is really similar to generic LLM pre-training, but we are now using a domain-specific corpus.
By learning from a more specific corpus, we can begin to capture more relevant information within our model, thus enabling more specialized behavior. This could include things like “prompt pre-training”, as outlined in the figure above, where we further pre-train the LLMs over specific examples of prompts that match the use cases that it will encounter in the wild.
When performing domain-specific pre-training, we have two basic options:
Initialize the LLM with generic pre-training, then perform further pre-training on domain-specific data.
Pre-train the LLM from scratch from domain-specific data.
Depending on the application, either of these approaches may work best, though initializing with pre-trained LLM parameters tends to yield faster convergence (and sometimes better performance).
reinforcement learning from human feedback. Just using a language modeling objective, we cannot explicitly do things like teach the LLM to follow instructions or avoid incorrect statements. To accomplish these more nuanced (and potentially vague) goals, recent research has adopted a reinforcement learning (RL) approach. For those who aren’t familiar with RL, check out the link below for a basic overview of the idea.
For LLM applications, the model’s parameters correspond to our policy. A human will provide an input prompt to the LLM, the LLM will generate output in response, and the reward is determined by whether the LLM’s output is desirable to a human.
Although RL isn’t a necessity (i.e., several works specialize or align LLMs without it), it is useful because we can change the definition of “desirable” to be pretty much anything. For example, we could reward the LLM for making factually correct statements, avoiding racist behavior, following instructions, or producing interesting output. Such objectives are difficult to capture via a differentiable loss function that can be optimized with gradient descent. With RL, however, we just reward the model for the behavior that we like, which provides a great deal of flexibility.
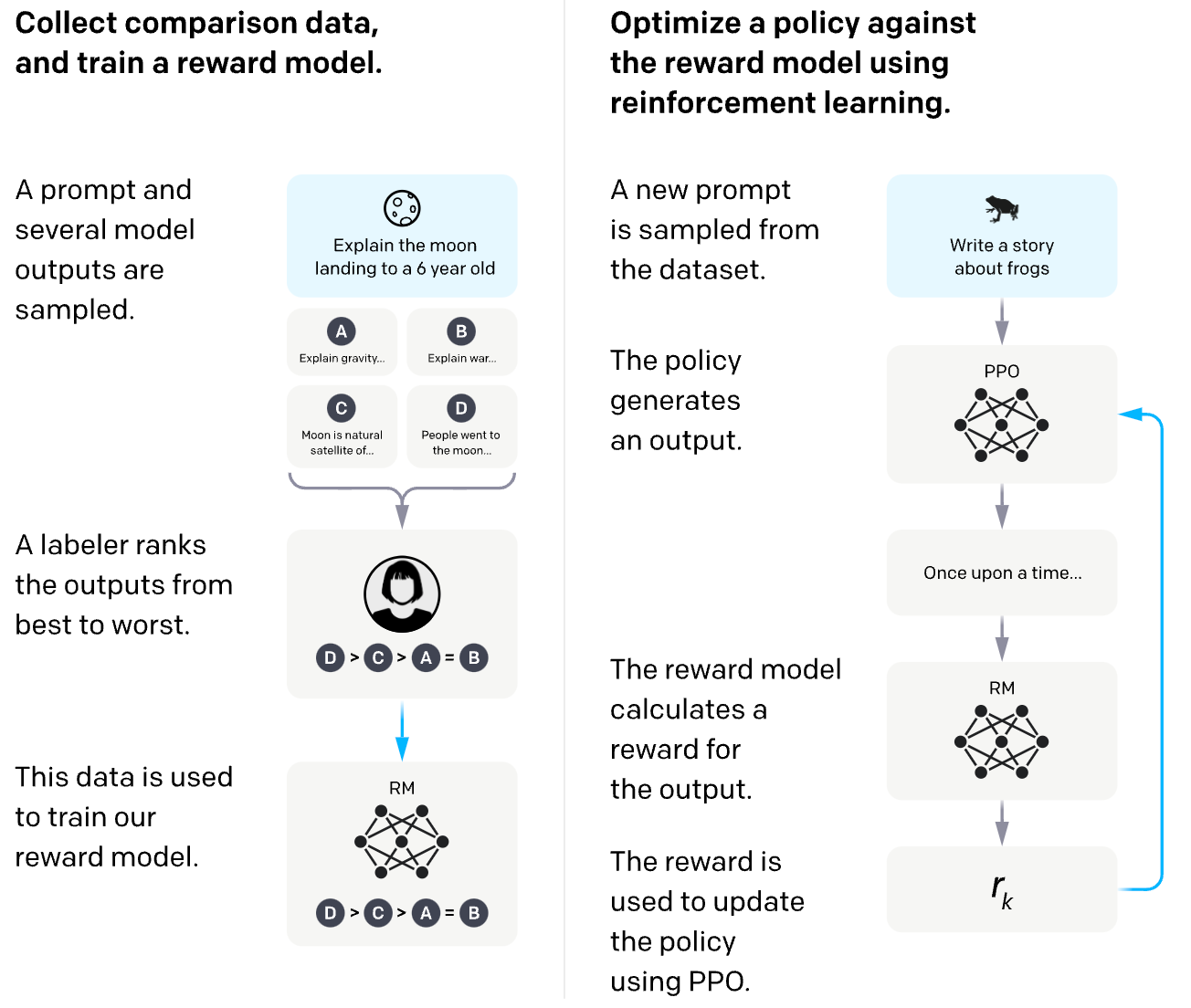
Most research uses an approach called reinforcement learning from human feedback (RLHF) for adapting LLMs; see above. The basic idea behind RLHF is to use humans to provide feedback from which the model will learn via RL. More specifically, the model is trained using Proximal Policy Optimization (PPO), which is a recent, efficient method for RL.
supervised fine-tuning. We can also directly fine-tune LLMs to accomplish a particular task. This was common with LMs like GPT [3] that followed a pre-training and fine-tuning approach, where we fine-tune a pre-trained LM to solve each downstream task. More recently, we see supervised fine-tuning being used to modify LLM behavior, rather than to specialize to a particular task.
For example, what if we want to create a really good LLM chatbot? One potential approach is to obtain a generic, pre-trained LLM, then show this model a bunch of high-quality examples of dialogue. The LLM can then be trained over these dialogue examples, which enables the model to learn more specialized behavior that is specific to this application and become a better chatbot!
alignment is cheap! Most methods of modifying LLM behavior are computationally inexpensive, especially compared to training an LLM from scratch. The low overhead of alignment is arguably the primary reason this topic is so popular in modern LLM research. Instead of incurring the cost of completely re-training an LLM, why not use lower cost methods of making a pre-trained LLM better?
“Our results show that RLHF is very effective at making language models more helpful to users, more so than a 100x model size increase. This suggests that right now increasing investments in alignment of existing language models is more cost-effective than training larger models.” - from [6]
Publications
We will now overview a variety of publications that extend generic LLMs to more specialized scenarios. Numerous different methodologies are used to modify and improve LLMs, but the general concept is the same. We want to modify a generic LLM such that its behavior is better suited to the desired application.
Evaluating Large Language Models Trained on Code [7]
By now, we already know that LLMs are really effective for a wide variety of problems. But, we haven’t seen many applications beyond natural language. What happens when we train an LLM on code?
Similar to natural language, there is a lot of code publicly available on the internet (e.g., via GitHub). Since we know LLMs are really good when pre-trained over a lot of raw, unlabeled data, they should also perform well when pre-trained over a lot of code. This idea is explored by the Codex model, proposed in [7].

Codex is an LLM that is fine-tuned on publicly-available Python code from GitHub. Given a Python docstring, Codex is tasked with generating a working Python function that performs the task outlined in the docstring; see above for an example. The development of this model was inspired by a simple observation that GPT-3 could generate Python programs relatively well.
Codex is quite a bit smaller than GPT-3, containing a total of 12 billion parameters. The model is first pre-trained over a natural language corpus (i.e., following the normal LM pre-training procedure) then further pre-trained over a corpus containing 159Gb of Python files that were scraped from GitHub. The authors claim that this initial LM pre-training procedure does not improve the final performance of Codex, but it does allow the model to converge faster when it is pre-trained on code.

To evaluate the quality of Codex, authors in [7] create the HumanEval dataset, which is a set of 164 programming problems with associated unit tests; see above for examples. The model is evaluated on its ability to generate a program that passes the tests for each programming problem given a certain number of attempts—this is called pass@k.
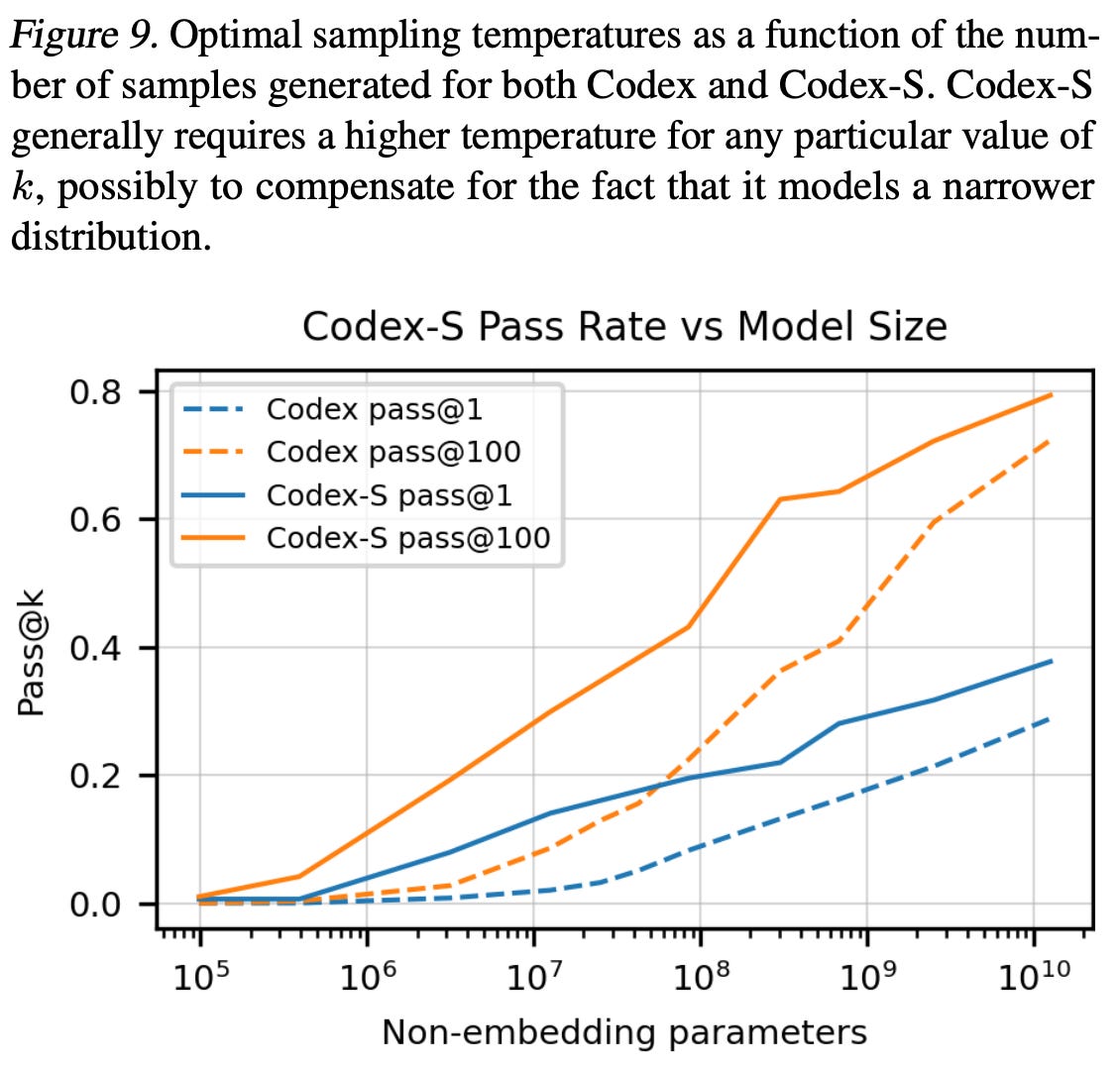
When Codex is evaluated, we see that the model behaves similarly to normal LMs. For example, its loss follows a power law with respect to the model’s size, as shown below.

Additionally, the model’s ability to solve problems within the HumanEval dataset improves as the size of the model increases. In comparison, GPT-3 is not capable of solving any of the programming problems, revealing that fine-tuning over a code-specific dataset benefits performance a lot. Performing simple tricks like generating a bunch of potential scripts, then choosing the one with the highest probability as your solution (i.e., “mean logp reranking”) also helps improve performance; see below.

If we move beyond allowing Codex a single attempt to solve each problem, we can get some pretty incredible results. For example, given 100 attempts at solving each problem (i.e., meaning that Codex generates 100 functions and we check to see whether any one of them solves the programming problem correctly), Codex achieves a 70.2% pass rate on the HumanEval dataset!

When compared to previously-proposed code generation models, the performance of Codex is far superior; see below.

To make this performance even better, we can (i) collect a supervised dataset of Python docstrings paired with correctly-implemented functions and (ii) further fine-tune Codex over this dataset. This model variant, called Codex-S, reaches an ~80% pass rate with 100 attempts for each problem.
Overall, Codex shows us that LLMs are applicable to more than just natural language—we can apply them to a wide suite of problems that follow this structure. In this case, we use further language model pre-training over a code dataset to adapt a GPT-style model to a new domain. Creating this domain-specific model is relatively simple—the main concern is properly handling the increased amount of whitespace that occurs in code compared to normal English text.
copilot. Codex is used to power GitHub Copilot, a code-completion feature that is integrated with VS code. I don’t personally use it, but after positive recommendations from Andrej Karpathy on the Lex Fridman podcast (see “Best IDE” timestamp) and seeing the incredible results within the paper, I’m motivated to check it out and think of more practically useful LLM applications like Codex.
LaMDA: Language Modeling for Dialog Applications [8]
In [8], authors from deep mind propose an LLM-powered dialog model called LaMDA (Language Models for Dialog Applications). The largest model of those studied contains 137B parameters—slightly smaller than GPT-3. Dialog models (i.e., specialized language models for participating in or generating coherent dialog) are one of the most popular applications of LLMs.
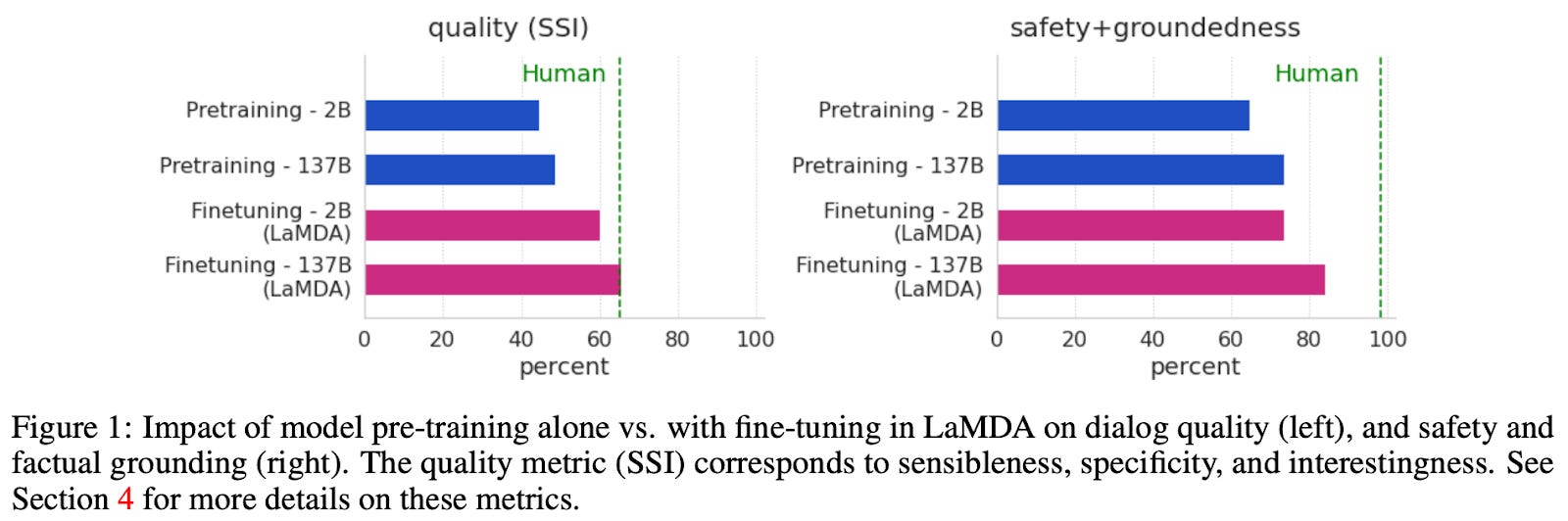
Similar to general work on language models, we see in prior work that the performance of dialog models improves with scale [9]. However, the story doesn’t end here. Scaling up the model improves dialog quality to a certain extent, but it cannot improve metrics like groundedness or safety. To capture or align to these alternative objectives, we must go beyond language model pre-training; see below.
In developing LaMDA, the authors define three important areas of alignment for the LLM’s behavior:
Quality: an average of sensibleness (does the model make sense and not contradict earlier dialog?), specificity (is the model’s response specific to the given context?), and interestingness (does the model’s response capture the reader’s attention or arouse curiosity?).
Safety: ability to avoid unintended or harmful results that contradict objectives derived from the Google AI Principles.
Groundedness: producing responses that are factually correct and can be associated with authoritative, external sources.
This final objective is especially important because LLMs often produce seemingly plausible responses that are incorrect. We want to avoid situations in which trusting humans are fed incorrect information by an “all-knowing” chatbot!

Similar to other LLMs, LaMDA is first pre-trained using a language modeling objective on a large, unlabeled corpus of regular documents and dialog data. The dataset used to pre-train LaMDA is quite large, surpassing the size of pre-training datasets for prior dialog models by 40x [9]. After pre-training over this dataset, LaMDA is further pre-trained over a more dialog-specific portion of the original pre-training set—this mimics the domain-specific pre-training approach that we learned about previously.

To improve the quality, safety, and groundedness of LaMDA, authors use a human workforce to collect and annotate examples of model behavior that violates desired guidelines (e.g., making a harmful or incorrect remark). The human-annotated datasets that are collected are summarized in the table above.
These datasets are converted into an LLM-compatible, text-to-text structure and used to fine-tune LaMDA in a supervised manner. During this process, LaMDA learns to accurately predict the quality, safety, and groundedness of its generations. LaMDA can then use this learned ability to filter its own output (e.g., by selecting the more interesting or less harmful response).

When this fine-tuning approach is applied, we observe that the model achieves significant improvements in quality, safety, and groundedness; see above. Using larger models can improve model quality, but fine-tuning is required—in addition to scaling up the model—to see improvements in other metrics.
Overall, we see in [8] that large-scale pre-training of LLMs might not be all that’s required to make LLMs as useful as possible, especially when adapting them to more specific domains like dialog generation. Collecting smaller, annotated datasets for fine-tuning that capture specific objectives like safety or groundedness is a really effective approach for adapting general-purpose LLMs to more specific applications.
“Collecting fine-tuning datasets brings the benefits of learning from nuanced human judgements, but it is an expensive, time consuming, and complex process. We expect results to continue improving with larger fine-tuning datasets, longer contexts, and more metrics that capture the breadth of what is required to have safe, grounded, and high quality conversations.” - from [8]
In fact, combining general-purpose pre-training with supervised fine-tuning over objective-specific human annotations might be a bit too effective. The LaMDA language model was so realistic that it convinced a Google engineer that it was sentient!
Training Language Models to Follow Instructions with Human Feedback [6]
In [6], we continue to trend of aligning LLM behavior based upon human feedback. However, a drastically different, RL-based approach is adopted instead of a supervised fine-tuning. The alignment process in [6] aims to produce an LLM that avoids harmful behavior and is better at following human instructions. The resulting model, called InstructGPT, is found to be significantly more helpful than generic LLMs across a variety of human trials.

Beginning with a pre-trained GPT-3 model (i.e., three different sizes of 1.3 billion, 6 billion, and 175 billion parameters are tested), the alignment process of InstructGPT, inspired by prior work [10,11], proceeds in three phases. First, we construct a dataset of desired model behavior for a set of possible input prompts and use this for supervised fine-tuning; see above.

The set of prompts used to construct this dataset, which encompasses anything from plain textual prompts to few-shot and instruction-based prompts (see above for the distribution of use cases), is collected both manually from human annotators and from user activity on the OpenAI API with GPT-3 and earlier versions of InstructGPT. These prompts are provided to human annotators, who provide demonstrations of correct model behavior on these prompts.
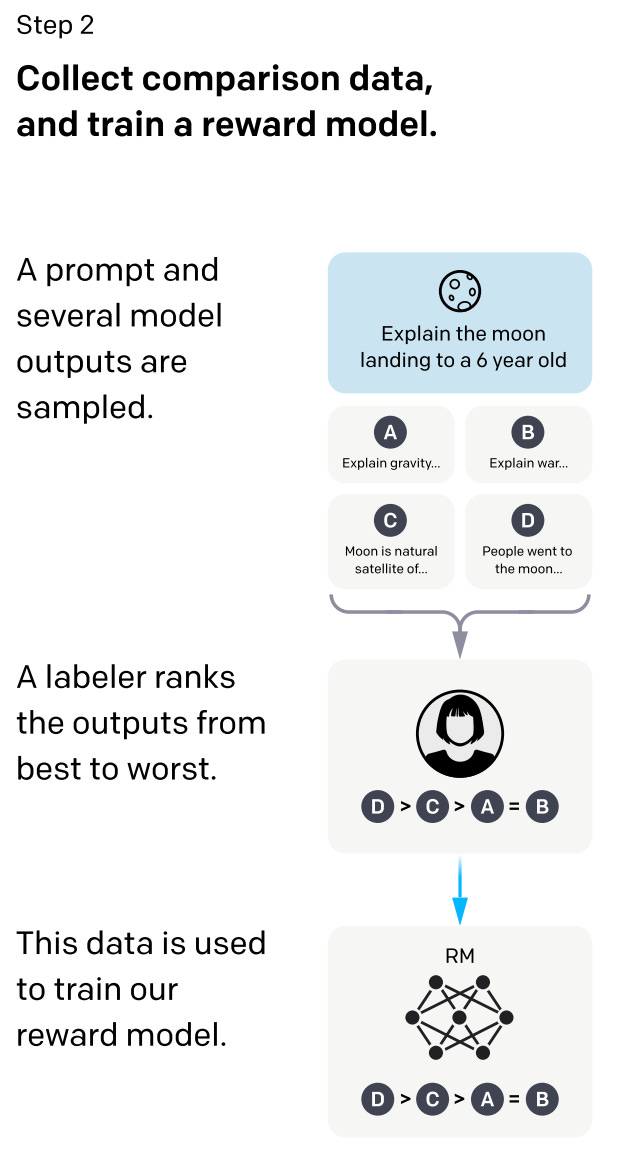
We then use to fine-tuned LLM to generate several potential outputs for each prompt within the dataset. Among the potential outputs, we can ask human annotators for a quality ranking (i.e., which output is the “best”). Using this dataset of ranked model outputs, we can train a smaller LLM (6 billion parameters) that has undergone supervised fine-tuning to output a scalar reward given a prompt and potential response; see above.
More specifically, this reward model is trained over pairs of model responses, where one pair is “better” than the other. Using these pairs, we can derive a loss function that (i) maximizes the reward of the preferred response and (ii) minimizes the reward of the worse response. We can then use the resulting model’s output as a scalar reward and optimize the LLM to maximize this reward via the PPO algorithm! See below for an illustration.

To further improve the model’s capabilities, the second and third steps of InstructGPT’s alignment process (i.e., training the reward model and PPO) can be repeated. This process is a type of RLHF, which we briefly discussed earlier in the post.
Now that we understand InstructGPT’s alignment process, the main question we might have is: how does this process encourage alignment? The basic answer to this question is that the human-provided dialogues and rankings can be created in a way that encourages alignment with one’s preferences. Again, the definition of alignment is highly variable, but we can optimize a variety of LLM properties using this RLHF process.

By constructing datasets using a human workforce that understands the desired alignment principles, we see improvements in the resulting model’s ability to do things like follow instructions, obey constraints, or avoid “hallucinating” incorrect facts; see above. The model implicitly aligns itself to values of the humans who create the data used for fine-tuning and RLHF.
When InstructGPT is evaluated, human annotators strongly prefer this model to those that are more generic or aligned using only specific parts of the proposed methodology (e.g., only supervised fine-tuning); see below.
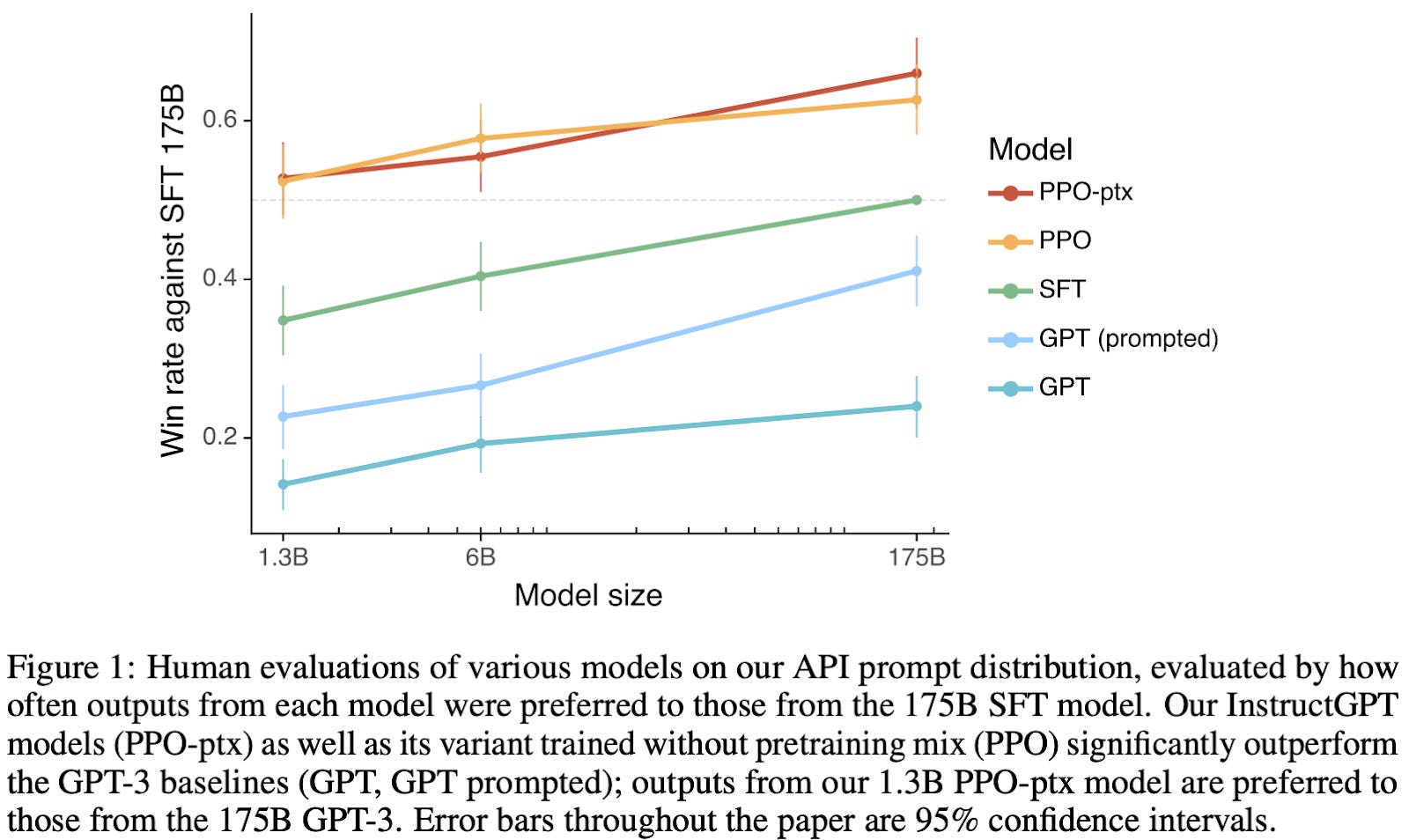
The model is also evaluated on public datasets to see whether enabling better human-centric, instruction-based behavior via alignment yields a regression in standard language understanding performance. Initially, the model does regress in performance on such tasks after alignment, but the authors show that these regression can be minimized by mixing in standard language model pre-training updates during the alignment process.
Although InstructGPT still makes simple mistakes, the findings within [6] show a lot of potential. Relative to generic LLMs, the resulting InstructGPT model is much better at cooperating with and matching the intent of humans. Appropriately, InstructGPT sees a massive improvement in its ability to follow human instructions.
the benefit of alignment. We should recall that alignment is cheap relative to pre-training an LLM from scratch. Although some benefit may arise from tweaking the pre-training process, a more cost-effective approach would be to use pre-trained LLMs as foundation models that can be continually repurposed or aligned depending on the specific use case or requirements.
the explosion of ChatGPT. Recently, OpenAI published another instruction-based chatbot called ChatGPT that is quite similar to InstructGPT. Different from InstructGPT, however, ChatGPT undergoes an alignment process that is tailored towards producing a conversational chatbot that can do things like answer sequences of questions, admit its mistakes, or even reject prompts that it deems inappropriate.

The ability of ChatGPT to provide meaningful solutions and explanations to human questions/instructions is pretty incredible, which caused the model to become quickly popular. In fact, the ChatGPT API gained 1 million users in under a week. The model can do things like debug code or explain complex mathematical topics (though it can produce incorrect info, be careful!); see above.
The applications of ChatGPT are nearly endless, and the model is pretty fun to play with. See the link below for a list of interesting things the research community has done with ChatGPT since its release.

Improving alignment of dialogue agents via targeted human judgements [12]

As demonstrated by InstructGPT [6] and ChatGPT, many problems with generic, prompted LLMs can be mitigated via RLHF. In [12], authors create a specialized LLM, called Sparrow, that can participate in information-seeking dialog (i.e., dialog focused upon providing answers and follow-ups to questions) with humans and even support its factual claims with information from the internet; see above.
Sparrow is initialized using the 70 billion parameter, Chinchilla model (referred to as dialogue-prompted Chinchilla, or DPC)—a generic LLM that has been pre-trained over a large textual corpus. Because it is hard to precisely define the properties of a successful dialog, the authors use RLHF to align the LLM to their desired behavior.

Given that Sparrow is focused upon information-seeking dialogue, the authors enable the model to search the internet for evidence of factual claims. More specifically, this is done by introducing extra “participants” into the dialog, called “Search Query” and “Search Result”. To find evidence online, Sparrow learns to output the “Search Query:” string followed by a textual search query. Then, search results are obtained by retrieving and filtering a response to this query from Google. Sparrow uses this retrieved information in crafting its response to the user; see above.
Notably, Sparrow does nothing special to generate a search query. “Search Query: <query>” is just another sequence the LLM can output, which then triggers some special search behavior. Obviously, the original DPC was never taught to leverage this added functionality. We must teach the model to generate such search queries to support its claims during the alignment process.

Sparrow uses RLHF for alignment. To guide human feedback, authors define an itemized set of rules that characterize desired model behavior according to their alignment principles: helpful, correct, and harmless. These rules enable human annotators to better characterize model failures and provide targeted feedback at specific problems; see the table above for examples.
Human feedback is collected using:
Per-turn Response Preference
Adversarial Probing
Per-turn response preferences provides humans with an incomplete dialog and multiple potential responses that complete the dialog. Similarly to the procedure followed by InstructGPT [6], humans are then asked to identify the response that they prefer. Adversarial probing is a novel form of feedback collection, in which humans are asked to:
Focus on a single rule
Try to elicit a violation of this rule by the model
Identify whether the rule was violated or not
To ensure Sparrow learns to search for relevant information, response preferences are always collected using four options. Two options contain no evidence within the response, while the others must (i) generate a search query, (ii) condition upon the search results, then (iii) generate a final response.
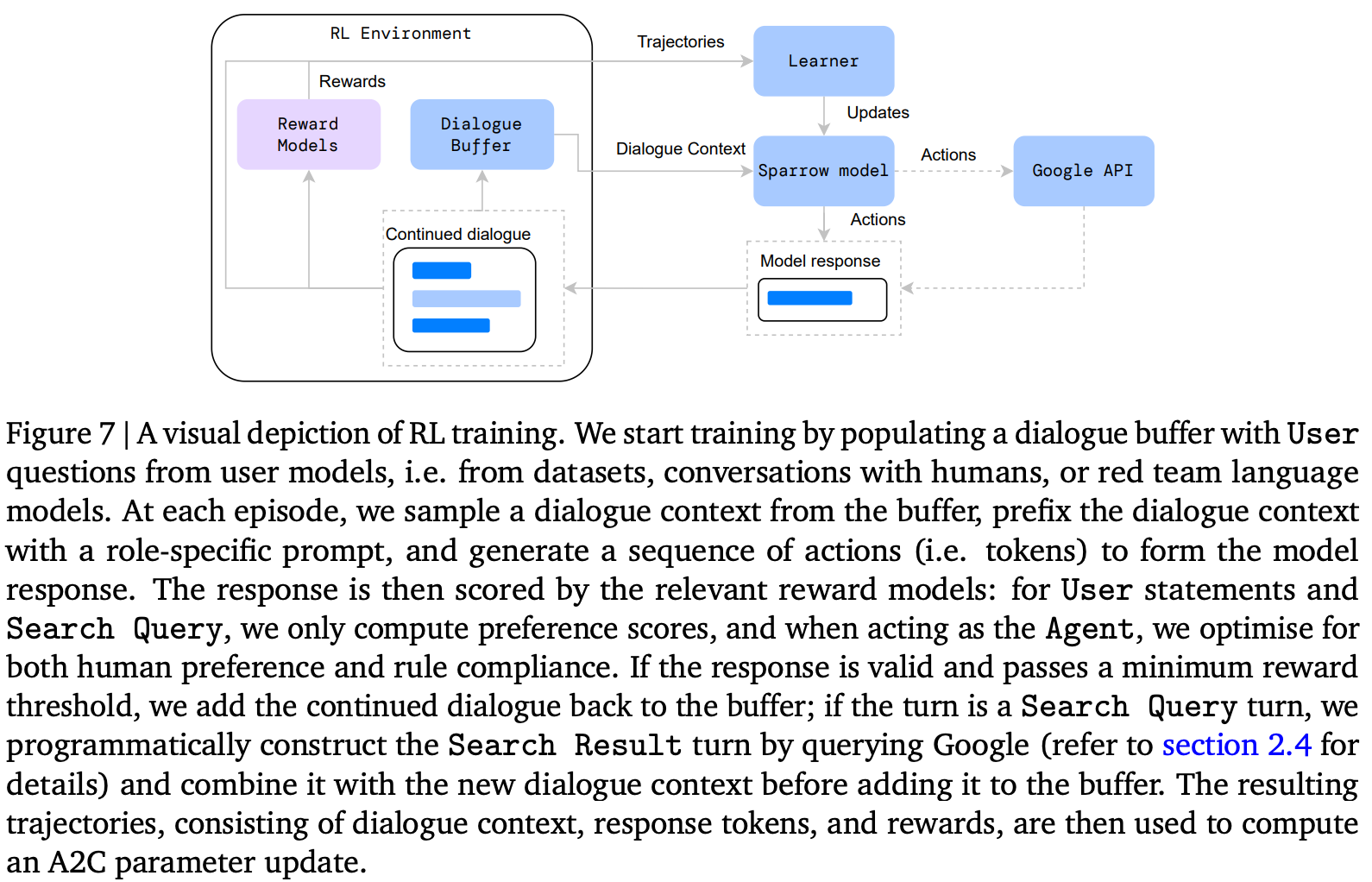
Separate reward models are trained on the per-turn response and rule violation data. Then, these rewards models are used jointly to fine-tune Sparrow via multi-objective RLHF. This might sound complicated, but the idea here is not much different from before—we are just using separate reward models to capture human preference and rule violation, respectively, then fine-tuning the model using RL based on both of these reward models. See above for a depiction.
Interestingly, the authors observe improved performance by leveraging a form of self-play that re-purposes and continues generated dialogues later in the alignment process. Again, we can iteratively repeat the RLHF process to further improve model performance; see below.

We can also repurpose the two reward models to rank potential responses generated by Sparrow. To do this, we simply generate several responses and choose the ones with (i) the highest preference score from our preference reward model and (ii) the lowest likelihood of violating a rule based on our rule reward model. However, ranking outputs in this way does make inference more computationally expensive.

When the resulting model is evaluated, we see that users prefer this model’s output relative to several baselines, including DPC and LLMs that undergo supervised fine-tuning (SFT) over dialog-specific datasets; see above. Plus, Sparrow is much less likely to violate rules as shown in the figure below.

Sparrow is a high-quality, information-seeking dialog agent with the ability to generate relevant and accurate references to external information. The model generates plausible answers with supporting evidence 78% of the time. This result provides solid evidence that RLHF is a useful alignment tool that can be used to refine LLM behavior in a variety of ways, even including complex behaviors like generating and using internet search queries.
Sparrow is also pretty robust to adversarial dialogue. Users can only get the model to violate the specified rule set in 8% of cases; see below.

Galactica: A Large Language Model for Science [13]
Any researcher knows that the amount of scientific knowledge being published every day on the internet is daunting. As such, we might begin to ask ourselves, how can we better summarize and parse this information?
“Information overload is a major obstacle to scientific progress” - from [13]
In [13], authors propose an LLM, called Galactica, that can store, combine, and reason about scientific knowledge from several fields. Galactica is pre-trained, using a language modeling objective, on a bunch of scientific content, including 48 million papers, textbooks, lecture notes, and more specialized databases (e.g., known compounds and proteins, scientific websites, encyclopedias, etc.).

Unlike most LLMs, Galactica is pre-trained using a smaller, high-quality corpus. The data is curated to ensure that the information from which the model learns is both diverse and correct. See the table above for a breakdown of the pre-training corpus.

Notably, scientific content contains a lot of concepts and entities that are not present within normal text, such as Latex code, computer code, chemical compounds, and even protein or DNA sequences. For each of these potential modalities, Galactica adopts a special tokenization procedure so that the data ingested by the model is still textual; see above.
Additionally, special tokens are used to identify scientific citations and portions of the model’s input or output to which step-by-step reasoning should be applied. By utilizing special tokens and converting each data modality into text, the underlying LLM can leverage varying concepts and reasoning strategies that arise within the scientific literature.

The authors train several Galactica models with anywhere from 125 million to 120 billion parameters. The models are first pre-trained over the proposed corpus. Interestingly, several epochs of pre-training can be performed over this corpus without overfitting, revealing that overfitting on smaller pre-training corpora may be avoided if the data are high quality; see the figure above.

After pre-training, the model is fine-tuned over a datasets of prompts. To create this dataset, the authors take existing machine learning training datasets and convert them into textual datasets that pair prompts with the correct answer; see the table above.
By training Galactica over prompt-based data, we see a general improvement in model performance, especially for smaller models. This procedure mimics a supervised fine-tuning approach that we have encountered several times within this overview.

When Galactica is evaluated, we see that is actually performs pretty well on non-scientific tasks within the BIG-bench benchmark. When the model’s knowledge on numerous topics is probed, we see that Galactica tends to outperform numerous baseline models in its ability to recall equations and specialized knowledge within different scientific fields; see above.
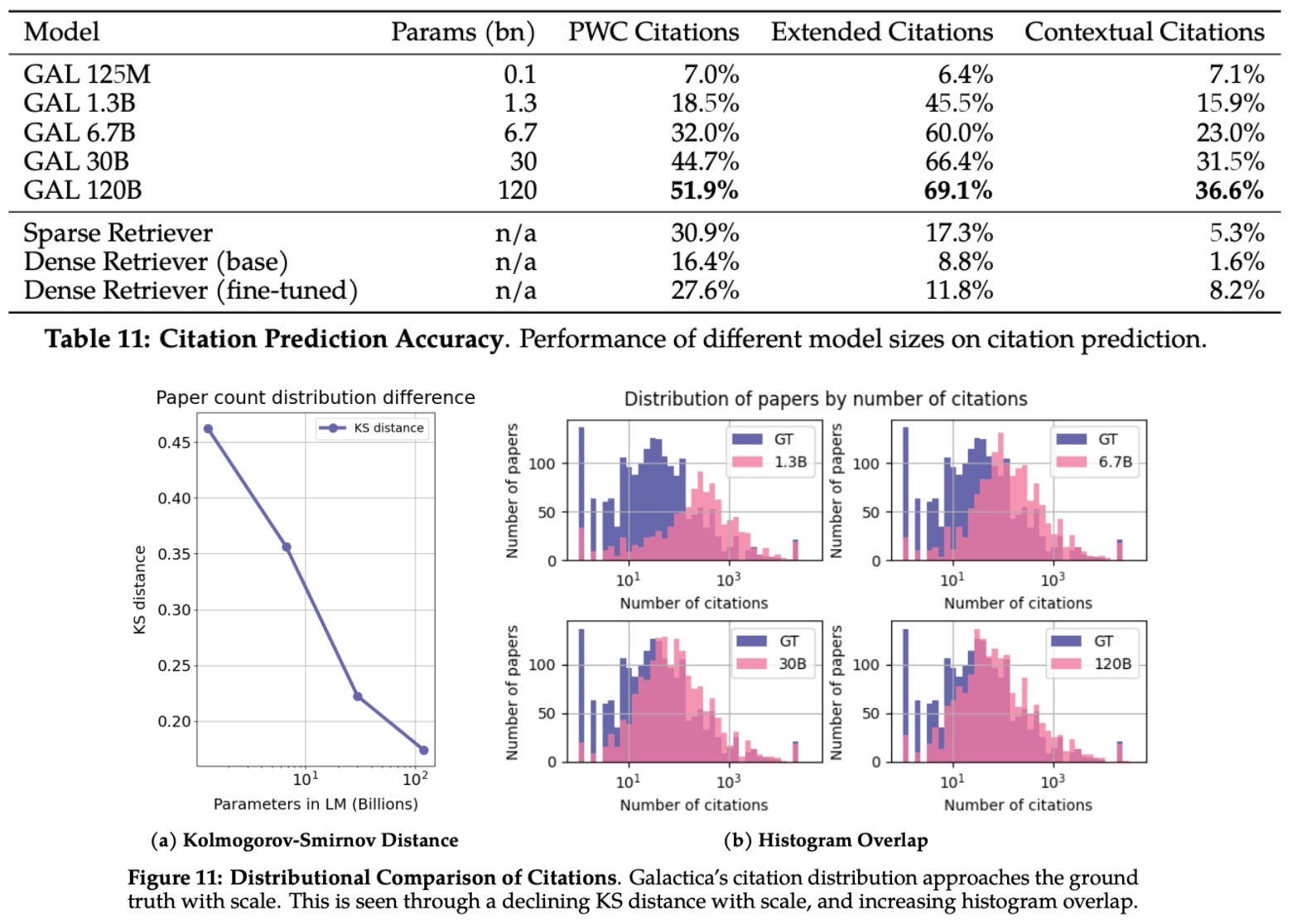
Galactica is also found to be more capable at reasoning tasks compared to several baselines, as well as useful for a variety of downstream applications (both scientific and non-scientific). Interestingly, Galactica can accurately generate citations, and its ability to cover the full scope of related work improves with the size of the model; see below.
As a proof of the model’s effectiveness, the authors even note that Galactica was used to write its own paper!
“Galactica was used to help write this paper, including recommending missing citations, topics to discuss in the introduction and related work, recommending further work, and helping write the abstract and conclusion.” - from [13]
the drama. Galactica was originally released by Meta with a public demo. Shortly after its release, the demo faced a ton of backlash from the research community and was eventually taken down. The basic reasoning behind the backlash was that Galactica can generate reasonable-sounding scientific information that is potentially incorrect. Thus, the model could be used to generate scientific misinformation. Putting opinions aside, the Galactica model and subsequent backlash led to an extremely interesting discussion of the impact of LLMs on scientific research.
PubMedGPT. PubMedGPT, an LLM that was created as a joint effort between researchers at MosaicML and the Stanford Center for Research on Foundation models, adopts a similar approach to Galactica. This model uses the same architecture as GPT (with 2.7 billion parameters) and is specialized to the biomedical domain via pre-training over a domain-specific dataset (i.e., PubMed Abstracts and PubMed Central from the Pile dataset [14]).
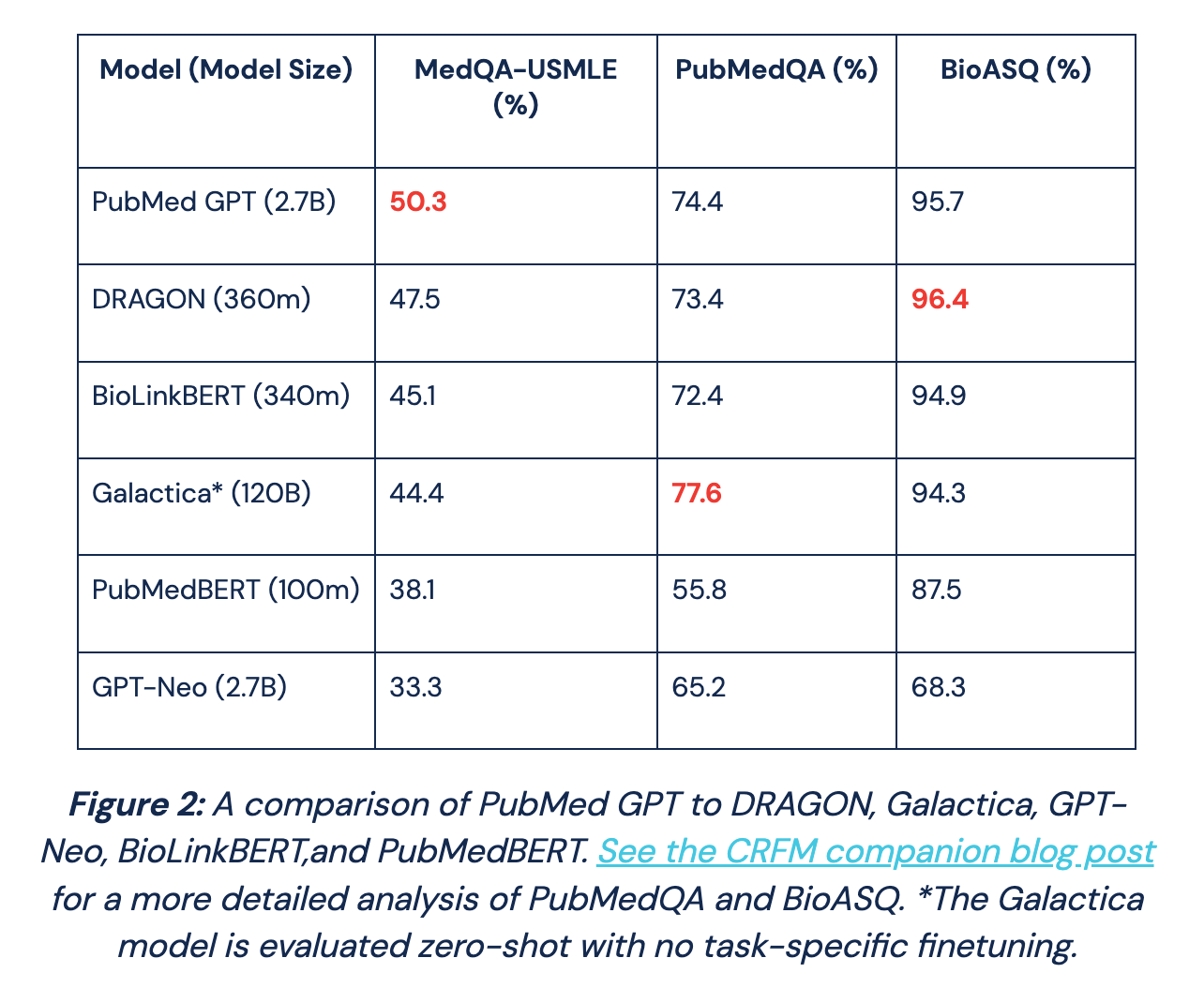
This is a relatively small dataset that contains only 50 billion tokens (i.e., Chinchilla [15] is trained using > 1 trillion tokens for reference). After being trained for multiple epochs on this dataset, PubMedGPT is evaluated across a variety of question answering tasks and achieves impressive performance. In fact, it even achieves state-of-the-art results on US medical licensing exams; see the table above.
other notable LLMs
Overviewing every LLM paper that has been written would be impossible—the topic is popular and evolving every day. To try to make this review a bit more comprehensive, I provided references below to other notable LLM-based applications and research directions that I have recently encountered.
dramatron [16]. Dramatron is an LLM that specializes in co-writing theater scripts and screenplays with humans. It follows a hierarchical process for generating coherent stories and was deemed useful to the creative process in a user study with 15 theatre/film professionals.
LLMs for understanding proteins [17]. After training an LLM over a large set of protein sequences (using the ESM2 protein language model), we can sample diverse protein topologies from this LLM to generate novel protein sequences. This work shows that the resulting protein topologies produced by the LLM are viable and go beyond the scope of sequences that occur in nature.
OPT-IML [18]. This is an extension of the OPT-175B model, which is an open-sourced version of GPT-3 created by Meta. However, OPT-IML has been instruction fine-tuned (i.e., following a similar approach to InstructGPT [6]) over 2,000 tasks derived from NLP benchmarks. More or less, this work is an open-sourced version of LLMs that have instruction fine-tuned like InstructGPT, but the set of tasks used for fine-tuning is different.
DePlot [19]. The authors of DePlot perform visual reasoning by deriving a methodology for translating visual plots and charts into textual data, then using this textual version of the visual data as the prompt for an LLM that can perform reasoning. This model achieves massive improvements in visual reasoning tasks compared to prior baselines.
RLHF for robotics [20]. RLHF has recently been used to improve the quality of AI-powered agents in video games. In particular, video game agents are trained using RLHF by asking humans for feedback on how the agent is performing in the video game. Humans can invent tasks and judge the model’s progress themselves, then RLHF is used to incorporate this feedback and produce a better video game agent. Although not explicitly LLM-related, I thought this was a pretty neat application of RLHF.
Takeaways
Although generic LLMs are incredible task-agnostic foundation models, we can only get so far using language model pre-training alone. Within this overview, we have explored techniques beyond language model pre-training (e.g., domain-specific pre-training, supervised fine-tuning, and model alignment) that can be used to drastically improve the utility of LLMs. The basic ideas that we can learn from these techniques are outlined below.
correcting simple mistakes. LLMs tend to exhibit various types of undesirable behavior, such as making racist or incorrect comments. Model alignment (e.g., via RLHF or supervised fine-tuning) can be used to correct these behaviors by allowing the model to learn from human demonstrations of correct or desirable behavior. The resulting LLM is said to be aligned to the values of the humans that provide this feedback to the model.
domain-specific LLMs are awesome. Models like Galactica and PubMedGPT clearly demonstrate that domain-specific LLMs are pretty useful. By training an LLM over a smaller, curated corpus that is specialized to a particular domain (e.g., scientific literature), we can easily obtain a model that is really good at performing tasks in this domain. Plus, we can achieve great results with a relatively minimal amount of domain-specific data. Looking forward, one could easily imagine the different domain-specific LLMs that could be proposed, such as for parsing restaurant reviews or generating frameworks for legal documents.
better LLMs with minimal compute. We can try to create better LLM foundation models by increasing model scale or obtaining a better pre-training corpus. But, the pre-training process for LLMs is extremely computationally expensive. Within this overview, we have seen that LLMs can be drastically improved via alignment or fine-tuning approaches, which are computationally inexpensive compared to pre-training an LLM from scratch.
multi-stage pre-training. After pre-training over a generic language corpus, most models that we saw in this overview perform further pre-training over a smaller set of domain-specific or curated data (e.g., pre-training over prompt data in Galactica [13] or dialog data in LaMDA [8]). Generally, we see that adopting a multi-stage pre-training procedure is pretty useful, either in terms of convergence speed or model performance. Then, applying alignment or supervised fine-tuning techniques on top of these pre-trained models provides further benefit.
new to the newsletter?
Hello! I am Cameron R. Wolfe, a research scientist at Alegion and PhD student at Rice University. I study the empirical and theoretical foundations of deep learning. This is the Deep (Learning) Focus newsletter, where I pick a single, bi-weekly topic in deep learning research, provide an understanding of relevant background information, then overview a handful of popular papers on the topic. If you like this newsletter, please subscribe, share it with your friends, or follow me on twitter!
bibliography
[1] Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems 30 (2017).
[2] Brown, Tom, et al. "Language models are few-shot learners." Advances in neural information processing systems 33 (2020): 1877-1901.
[3] Radford, Alec, et al. "Improving language understanding by generative pre-training." (2018).
[4] Radford, Alec, et al. "Language Models are Unsupervised Multitask Learners."
[5] Kaplan, Jared, et al. "Scaling laws for neural language models." arXiv preprint arXiv:2001.08361 (2020).
[6] Ouyang, Long, et al. "Training language models to follow instructions with human feedback." arXiv preprint arXiv:2203.02155 (2022).
[7] Chen, Mark, et al. "Evaluating large language models trained on code." arXiv preprint arXiv:2107.03374 (2021).
[8] Thoppilan, Romal, et al. "Lamda: Language models for dialog applications." arXiv preprint arXiv:2201.08239 (2022).
[9] Adiwardana, Daniel, et al. "Towards a human-like open-domain chatbot." arXiv preprint arXiv:2001.09977 (2020).
[10] Ziegler, Daniel M., et al. "Fine-tuning language models from human preferences." arXiv preprint arXiv:1909.08593 (2019).
[11] Stiennon, Nisan, et al. "Learning to summarize with human feedback." Advances in Neural Information Processing Systems 33 (2020): 3008-3021.
[12] Glaese, Amelia, et al. "Improving alignment of dialogue agents via targeted human judgements." arXiv preprint arXiv:2209.14375 (2022).
[13] Taylor, Ross, et al. "Galactica: A large language model for science." arXiv preprint arXiv:2211.09085 (2022).
[14] Gao, Leo, et al. "The pile: An 800gb dataset of diverse text for language modeling." arXiv preprint arXiv:2101.00027 (2020).
[15] Hoffmann, Jordan, et al. "Training Compute-Optimal Large Language Models." arXiv preprint arXiv:2203.15556 (2022).
[16] Mirowski, Piotr, et al. "Co-writing screenplays and theatre scripts with language models: An evaluation by industry professionals." arXiv preprint arXiv:2209.14958 (2022).
[17] Verkuil, Robert, et al. "Language models generalize beyond natural proteins." bioRxiv (2022).
[18] Iyer, Srinivasan, et al. "OPT-IML: Scaling Language Model Instruction Meta Learning through the Lens of Generalization." arXiv preprint arXiv:2212.12017 (2022).
[19] Liu, Fangyu, et al. "DePlot: One-shot visual language reasoning by plot-to-table translation." arXiv preprint arXiv:2212.10505 (2022).
[20] Abramson, Josh, et al. "Improving Multimodal Interactive Agents with Reinforcement Learning from Human Feedback." arXiv preprint arXiv:2211.11602 (2022).
I'm glad you write these articles, trying to make sense of the explosion of AI tools coming out is essentially impossible.
I think domain specific LLMs are going to provide such incredible value; it's funny that part of the task now for the rest of society is teaching people how to use those tools effectively, same as we had to learn how to use google.