


Saga of the Lottery Ticket Hypothesis
How winning tickets were discovered, debunked, and re-discovered

How winning tickets were discovered, debunked, and re-discovered

The Lottery Ticket Hypothesis (LTH) is related to neural network pruning and can be concisely summarized via the following statement [1]:
“dense, randomly-initialized, feed-forward networks contain subnetworks (winning tickets) that — when trained in isolation — reach test accuracy comparable to the original network in a similar number of iterations.”
Though a bit difficult to interpret, such a statement reveals that if we:
Train a neural network to convergence
Prune its weights, yielding a smaller subnetwork
Rewind subnetwork weights to their original, randomly-initialized values
Train the resulting subnetwork to convergence
Then, the subnetwork — typically called a “winning ticket” — will achieve testing accuracy that matches or exceeds the performance of the original, dense neural network from which the subnetwork was derived.
Such an observation was intriguing to the deep learning community, as it means random subnetworks exist within dense networks that (i) are smaller/more computationally efficient and (ii) can be independently trained to perform well. If these winning tickets can be identified easily, neural network training cost can be drastically reduced by simply training the subnetwork instead of the full, dense model.
The goal of reducing training complexity via LTH-inspired findings has not yet been realized due to the fact that discovering winning tickets requires full (or partial [2]) pre-training of the dense network, which is a computationally burdensome process. But, the deep learning community continues to study the LTH because of its potential to inform and simplify neural network training.
Background Information
Prior to diving into the main topic, I am going to provide relevant background information needed to understand the LTH. I aim to build a ground-up understanding of the topic by providing a comprehensive summary of relevant context. In some cases, however, providing a full overview of a topic is not practical or within scope, so I instead provide links to external resources that can be used to grasp an idea more deeply.
What is neural network pruning?
In order to fully understand the LTH, one must be familiar with neural network pruning [3, 4, 5], upon which the LTH is based. The basic idea behind pruning is to remove parameters from a large, dense network, yielding a (possibly sparse) subnetwork that is smaller and more computationally efficient. Though I cite some of the most useful papers on neural network pruning here, numerous high-quality resources exist online that are helpful to explore.
Ideally, the pruned subnetwork should perform similarly to the dense network, though this may not be the case if a large number of parameters are removed. Thus, the goal of the pruning process is to find and remove parameters that do not significantly impair the network’s performance.
In most cases, neural network pruning follows the three-step process of pre-training, pruning, and fine-tuning. The dense network is first pre-trained, either partially or to convergence. Then, pruning is performed on this dense network, and the resulting subnetwork is further trained/fine-tuned after pruning occurs.
Different Types of Pruning
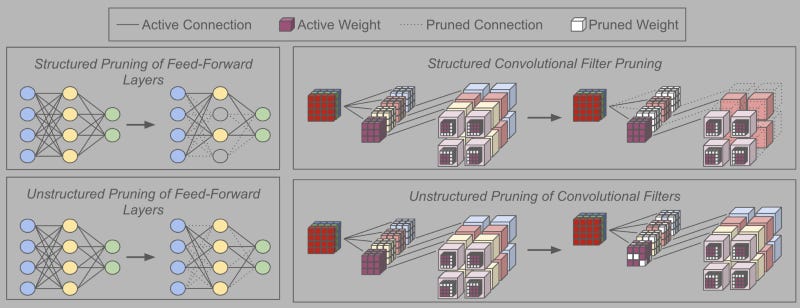
Many techniques for neural network pruning exist, but they can be roughly categorized into two groups — structured and unstructured pruning.
Unstructured pruning places no constraints on the pruning process. Any and all weights within the network can be individually pruned/removed, meaning that the resulting network is oftentimes sparse after pruning is performed.
In contrast, structured pruning removes entire “groups” of weights (e.g., convolutional filters, neurons in feed-forward layers, attention heads in transformers, etc.) together from the underlying network to avoid sparsity in the resulting subnetwork. As a result, the subnetwork is just a smaller, dense model.
Both structured and unstructured pruning methodologies (depicted in the figure above) are widely used — neither one is necessarily “better”. Unstructured pruning allows higher sparsity levels to be reached without performance degradation because it places fewer constraints on the pruning process. However, structured pruning has the added benefit of producing dense subnetworks, thus allowing the use of specialized libraries for sparse matrix multiplication — which typically make network training/inference much slower — to be avoided.
Iterative Magnitude Pruning (IMP)

The type of neural network pruning that is most commonly-used for studying the LTH is iterative magnitude pruning (IMP) [4], which operates as follows:
Begin with a fully-trained, dense model
Select and prune the lowest magnitude weights in the network
Fine-tune/train the resulting subnetwork to convergence
Repeat steps (2)-(3) until the desired pruning ratio is achieved
Although the idea behind IMP is seemingly simple, this approach works incredibly well in practice and has proven itself a difficult baseline to beat [4, 5]. Because IMP works so well, numerous helpful explanations are available online.
IMP is sometimes modified when applied to structured pruning or used on more complex network variants. For example, one variant of IMP for structured filter pruning in convolutional neural networks assigns separate scaling factors to each channel within the network, then prunes filters based on the magnitude of these factors instead of the weights themselves [8]. See the image above for a schematic depiction.
Publications
Here, I will overview three important papers relevant to the LTH. The first work I consider proposes the LTH, while the others further analyze the idea and provide useful insight. Interestingly, the LTH was partially debunked shortly following its proposal, then later confirmed (with modifications) in a followup paper by the original authors. Contention around the topic led to a lot of confusion within the research community, and I’ll try my best to clear up that confusion here.
The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks [1]

Main Idea. Models can be easily pruned to <10% of total parameters. But, if we:
Took the structure/architecture of a pruned network
Randomly re-initialized its parameters
Trained the network from scratch
The subnetwork would perform poorly. This paper finds that special subnetworks — referred to as “winning tickets” — exist within a randomly-initialized, dense network that, when trained in isolation, can match the performance of the fully-trained dense network. Such a phenomenon was coined as the Lottery Ticket Hypothesis (LTH), as explained in the initial paragraph of this overview.
Methodology. To verify the LTH, authors adopt an unstructured pruning approach. The pruning technique used is quite similar to IMP with one minor difference. Namely, to produce winning tickets, the authors proceed as follows:
Begin with a fully-trained, dense model
Select and prune the lowest magnitude weights in the network
Rewind remaining subnetwork parameters to their initial, random values
Train the subnetwork to convergence
Repeat steps (2)-(4) until the desired pruning ratio is achieved
The main difference between the methodology above and IMP is the rewinding of model parameters. Instead of simply fine-tuning existing model parameters after pruning, parameters are reset to their original, random values.
In this way, the winning ticket — both its structure and its weights — exists within the randomly-initialized dense network. Thus, this subnetwork is shown to have won the “initialization lottery”, as it can be trained from scratch to higher accuracy than that of a fully-trained dense network or randomly re-initialized subnetwork with the same structure.
Findings.
The LTH is empirically validated using fully-connected networks and small-scale CNNs on MNIST and CIFAR10 datasets. Winning tickets that are 10–20% of the original network size are found to consistently exist.
Winning tickets are shown to have better generalization properties than the original dense network in many cases.
Randomly re-initializing winning tickets prior to training is damaging to performance. Rewinding parameters to their initial, random values is essential to matching or exceeding dense network performance.
Rethinking the Value of Network Pruning [5]
Main Idea. Put simply, this paper shows that subnetworks that are randomly re-initialized and trained from scratch perform similarly to subnetworks obtained via IMP. Such a result contradicts previous findings in the neural network pruning literature [1, 4], revealing that training large, overparameterized models is not actually necessary to obtaining a more efficient subnetwork.
Although this result is more relevant to general neural network pruning (i.e., not the LTH in particular), the results in this paper demonstrate that:
Rewinding subnetwork parameters to their initial values is not a necessary component of the LTH methodology — the same results can be obtained by randomly re-initializing subnetwork parameters during iterative pruning.
The LTH is a phenomenon that cannot be replicated in large-scale experiments with structured pruning and complex network architectures.
Methodology. Unlike the original LTH publication, the authors within this work utilized structured pruning approaches in the majority of their experiments. Though unstructured pruning is adopted in some cases, structured pruning is more commonly used in larger-scale experiments (e.g., structured filter pruning with convolutional networks [4]), making such an approach more appropriate.
A large variety of network pruning approaches are explored (see Section 4 headers and descriptions in [5]) that perform:
Pre-defined structure pruning: prune each layer a fixed, uniform amount
Automatic structure pruning: dynamically decide how much each layer should be pruned instead of pruning layers uniformly
Unstructured IMP: see the previous discussion on IMP for a description
For each of these approaches, the authors follow the previously-described three-step pruning process. For the third step, resulting subnetworks are trained beginning with various different parameter initializations:
Rewinding subnetwork parameters to their initial, random values
Retaining/fine-tuning existing subnetwork parameters
Randomly re-initializing subnetwork parameters
The authors find that randomly re-initializing subnetwork parameters after pruning matches or exceeds the performance of other approaches in a majority of cases. Thus, for such large-scale experiments, the LTH could not be validated.
Findings.
A random re-initialization of subnetwork parameters is sufficient to achieve competitive subnetwork performance, revealing that the LTH does not hold in the larger-scale experiments explored in this work.
The disparity in findings between the LTH and this paper may be caused by (i) mostly using structured pruning for analysis, (ii) using larger models and datasets, or (iii) difference in optimization and hyperparameter settings.
The parameters of winning tickets or high-performing subnetworks obtained from neural network pruning are not essential, revealing that neural network pruning may be no more than an alternative form of Neural Architecture Search.
Linear Mode Connectivity and the Lottery Ticket Hypothesis [6]

Main Idea. This work explores the problem outlined in the paper above — why does the LTH not hold in large-scale experiments? The authors find that winning tickets cannot be discovered in large-scale experiments using the methodology proposed in [1]. Namely, such subnetworks do not achieve accuracy that matches or exceeds that of the dense network.
Interestingly, however, if one modifies this procedure to rewind weights to some early training iteration k — rather than strictly to initialization — the resulting subnetwork performs well. Thus, the LTH still holds in large-scale experiments if the methodology is slightly modified as follows:
Begin with a fully-trained, dense model
Select and prune the lowest magnitude weights in the network
Rewind subnetwork parameters to values at training iteration k
Train the subnetwork to convergence
Repeat steps (2)-(4) until the desired pruning ratio is achieved
Because such subnetworks are not discovered within the randomly-initialized, dense network, the authors refer to them as “matching” subnetworks instead of winning tickets.
Methodology. To discover this interesting weight rewinding property within the LTH, the authors adopt a novel form of instability analysis based upon linear mode connectivity. Their method of analysis performs the following steps:
Create two copies of a network.
Train these networks independently with different random seeds, such that the networks experience different random noise and data ordering during training with stochastic gradient descent.
Determine if the two resulting networks are linearly connected by a region of non-increasing error.
In practice, the final step in the methodology above is performed by just testing a fixed number of linearly-interpolated points between the weights of the two networks. At each of these points, the error of the interpolated network is tested to ensure it does not exceed the average error values of the actual networks.
By performing instability analysis as described above, the authors discover that networks become stable early in training, but not at initialization. Furthermore, matching subnetworks are always stable, revealing that matching subnetworks cannot be derived from randomly-initialized, unstable parameters. Such an observation explains why the LTH only holds when weights are rewound to some early training iteration and not all the way to initialization.
Findings.
The LTH does not hold at scale. But, “matching” subnetworks can be discovered by modifying the LTH to rewind weights to some early iteration of training, instead of all the way to initialization.
Only very small-scale networks and datasets (e.g., LeNet on MNIST) are stable at initialization, which explains why the original LTH formulation [1] could only be verified on such small-scale datasets.
Given such modifications to the LTH, matching subnetworks can be found consistently even in large-scale experiments with state-of-the-art convolutional neural network architectures on ImageNet.
Takeaways
By studying the LTH, we have learned about several useful concepts:
Neural Network Pruning: generates a smaller, efficient network from a fully-trained dense network by removing unneeded weights
Structured vs. Unstructured Pruning: two categories of pruning methodologies that place different constraints on the pruning process
Iterative Magnitude Pruning: a simple, yet effective, pruning methodology that iteratively discards lowest-magnitude weights in the network
Linear Mode Connectivity: a property used to describe a network that is “stable” to the noise from training with stochastic gradient descent.
In the work that was overviewed, we first learned that — in small-scale experiments — dense, randomly-initialized neural networks contain subnetworks (i.e., winning tickets) that can be discovered with IMP and trained in isolation to achieve high accuracy [1].
This finding was later contradicted by research showing that, in large-scale experiments, such winning tickets can be randomly re-initialized and still achieve comparable accuracy, revealing that there is nothing special about these winning tickets other than the network structure discovered by IMP [5].
Such contradictory results were settled when it was shown that although winning tickets may not exist in randomly-initialized dense networks, matching subnetworks (i.e., subnetworks that match or exceed dense network performance) can be found via IMP in networks that have been trained a small amount [6]. Thus, the LTH is still valid at scale given some slight modifications.
Conclusion
Thanks so much for reading this article. If you liked it, please subscribe to my Deep (Learning) Focus newsletter, where I contextualize, explain, and examine a single, relevant topic in deep learning research every two weeks. Feel free to follow me on medium or visit my website, which has links to my social media and other content. If you have any recommendations/feedback, contact me directly or leave a comment.
Bibliography
[1] Frankle, Jonathan, and Michael Carbin. “The lottery ticket hypothesis: Finding sparse, trainable neural networks.” arXiv preprint arXiv:1803.03635 (2018).
[2] You, Haoran, et al. “Drawing early-bird tickets: Towards more efficient training of deep networks.” arXiv preprint arXiv:1909.11957 (2019).
[3] LeCun, Yann, John Denker, and Sara Solla. “Optimal brain damage.” Advances in neural information processing systems 2 (1989).
[4] Li, Hao, et al. “Pruning filters for efficient convnets.” arXiv preprint arXiv:1608.08710 (2016).
[5] Liu, Zhuang, et al. “Rethinking the value of network pruning.” arXiv preprint arXiv:1810.05270 (2018).
[6] Frankle, Jonathan, et al. “Linear mode connectivity and the lottery ticket hypothesis.” International Conference on Machine Learning. PMLR, 2020.
[7] You, Haoran, et al. “Drawing early-bird tickets: Towards more efficient training of deep networks.” arXiv preprint arXiv:1909.11957 (2019).
[8] Liu, Zhuang, et al. “Learning efficient convolutional networks through network slimming.” Proceedings of the IEEE international conference on computer vision. 2017.