


Language Models: GPT and GPT-2
How smaller language models inspired modern breakthroughs…


This newsletter is supported by Alegion. At Alegion, I work on a range of problems from online learning to diffusion models. Feel free to check out our data annotation platform or contact me about potential collaboration/opportunities!
If you like this newsletter, please subscribe, share it, or follow me on twitter. Thank you for your support!
Language models like GPT-3 [7] have revolutionized modern deep learning applications for NLP, leading to widespread publicity and recognition. Interestingly, however, most of the technical novelty of GPT-3 was inherited from its predecessors GPT and GPT-2 [1, 2]. As such, a working understanding of GPT and GPT-2 is useful for gaining a better grasp of current approaches for NLP.
The basic methodology explored by the GPT and GPT-2 models is simple. In fact, it can be boiled down to only a few steps:
Pre-train a language model using a lot of raw textual data
Adapt this pre-trained model to solve a downstream tasks
However, the description is a bit vague. How does pre-training work for language models? How do we “adapt” the language model to solve different tasks?
In this overview, we will build a fundamental understanding of language modeling, its use within GPT and GPT-2, and how it can be used to solve problems beyond just generating coherent text. Though GPT and GPT-2 are somewhat outdated due to the recent proposal of larger, more capable models, the fundamental concepts upon which they are built are still highly relevant to modern deep learning applications. Let’s take a closer look.
Prerequisites for GPT
The basic intuition behind GPT and GPT-2 is to use generic, pre-trained language models to solve a variety of language modeling tasks with high accuracy. To fully understand this approach, we have to first cover some fundamental concepts about how language models work and how they are leveraged within GPT and GPT-2.
language modeling
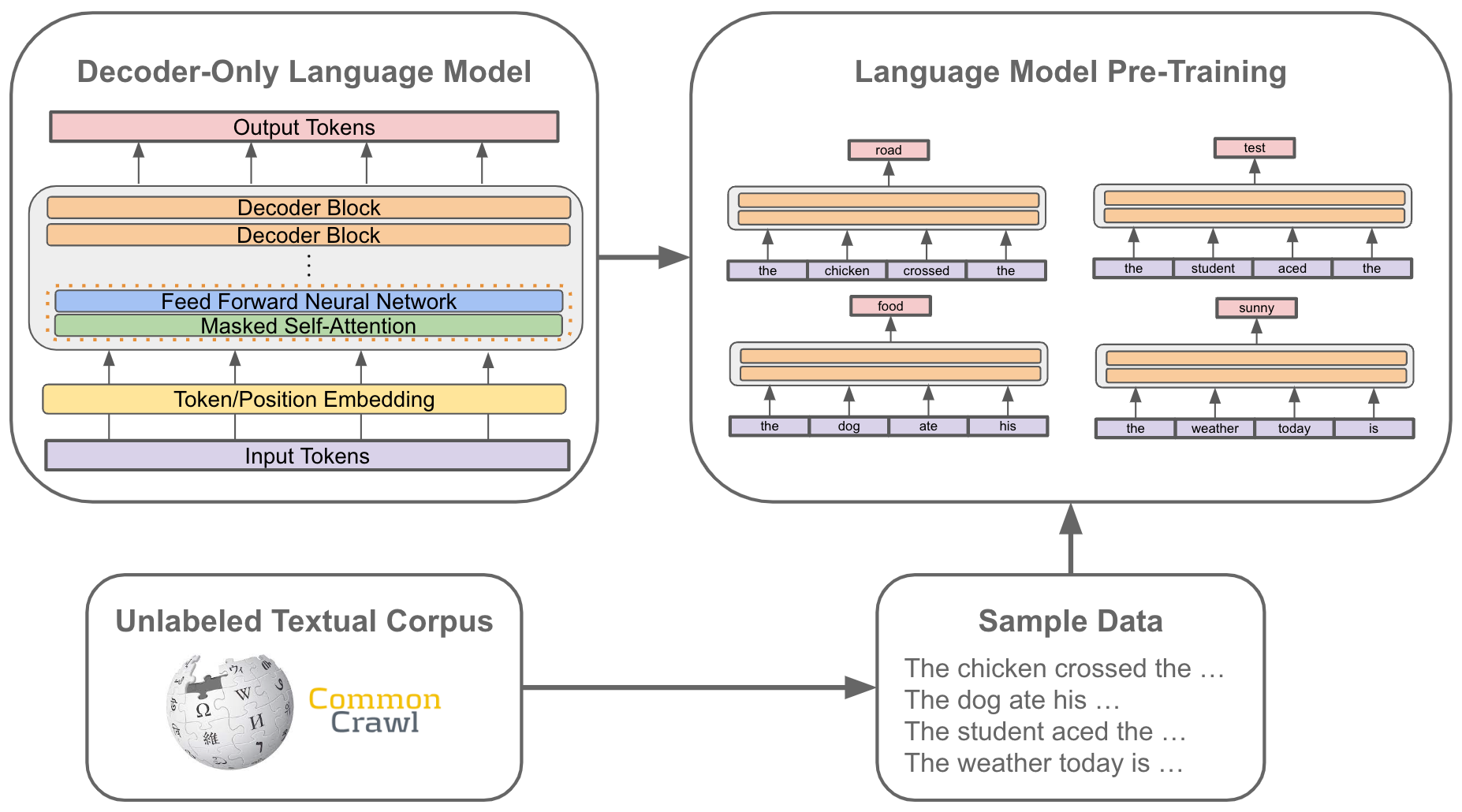
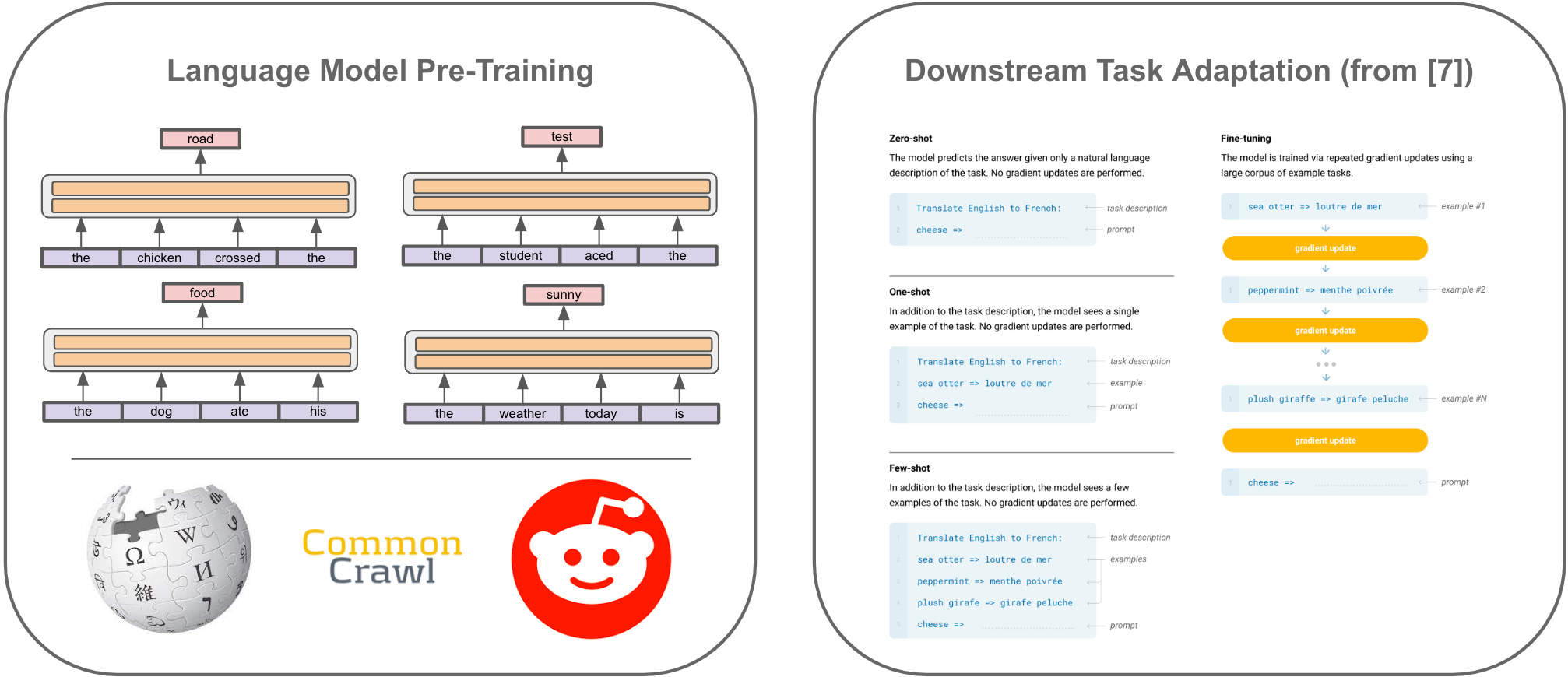
GPT models are pre-trained over a corpus/dataset of unlabeled textual data using a language modeling objective. Put simply, this means that we train the model by (i) sampling some text from the dataset and (ii) training the model to predict the next word; see the illustration above. This pre-training procedure is a form of self-supervised learning, as the correct “next” word can be determined by simply looking at the next word in the dataset.
language modeling in math. To understand language modeling, we only need to grasp the basic idea outlined above. To make this a bit more rigorous, however, we can notice that our corpus is just a set of tokens. We can think of tokens as individual words within the dataset, but this is not quite correct. In reality, tokens may be sub-words or even characters; see below for more details.
Let us denote this set of tokens (of size N) that comprise our pre-training dataset as follows.

Given a deep learning model with parameters θ, a language modeling objective tries to maximize the likelihood shown below.

Put simply, this expression characterizes the model’s probability of predicting the correct next token given k preceding tokens as context. For anyone who might be struggling to understand this formulation, feel free to check out the helper links below.
Using the language modeling loss (which just characterizes our model’s ability to accurately predict the next token in a sequence!), we can follow the procedure below to pre-train our model’s parameters θ such that the loss is minimized:
Sample text from the pre-training corpus
Predict the next token with our model
Use stochastic gradient descent (SGD), or any other optimizer, to increase the probability of the correct next token
By repeating this (self-supervised) training procedure many times, our model will eventually become really good at language modeling (i.e., predicting the next token in a sequence).
what is a language model? Models pre-trained using such a self-supervised language modeling objective are commonly referred to as language models (LMs). LMs become more effective as they are scaled up (i.e., more layers, parameters, etc.). Thus, we will often see larger versions of these models (e.g., GPT-3 [7]), which are referred to as large language models (LLMs).
why are LMs useful? LMs can generate coherent text by iteratively predicting the most likely next token, which enables a range of applications from text auto-completion to chatbots. Beyond their generative capabilities, however, prior work in NLP has shown that LM pre-training is incredibly beneficial for a variety tasks; e.g., pre-trained word embeddings are useful in downstream tasks [3, 4] and LM pre-training improves the performance of LSTMs [5].
Moving beyond such approaches, GPT models explore language model pre-training with transformers [6]. Compared to sequential models (e.g., LSTM), transformers are (i) incredibly expressive (i.e., high representational capacity, many parameters, etc.) and (ii) better suited to the ability of modern GPUs to parallelize computation, allowing LM pre-training to be performed with larger models and more data. Such scalability enables the exploration of LLMs, which have revolutionized NLP applications.
decoder-only transformers
Both GPT and GPT-2 use a decoder-only transformer architecture. I have previously summarized this architecture, but I will provide a quick overview here for completeness. To learn more about the transformer architecture, I would recommend briefly reading the explanation linked below.
The transformer architecture has two major components: the encoder and the decoder.

A decoder-only architecture removes the following components from the transformer:
The entire encoder module
All encoder-decoder self-attention modules in the decoder
After these components have been removed, each layer of the decoder simply consists of a masked self-attention layer followed by a feed forward neural network. Stacking several of such layers on top of each other forms a deep, decoder-only transformer architecture, such as those used for GPT or GPT-2; see below.

why the decoder? The choice of using the decoder architecture (as opposed to the encoder) for LMs is not arbitrary. The masked self-attention layers within the decoder ensure that the model cannot look forward in a sequence when crafting a token’s representation. In contrast, bidirectional self-attention (as used in the encoder) allows each token’s representation to be adapted based on all other tokens within a sequence.
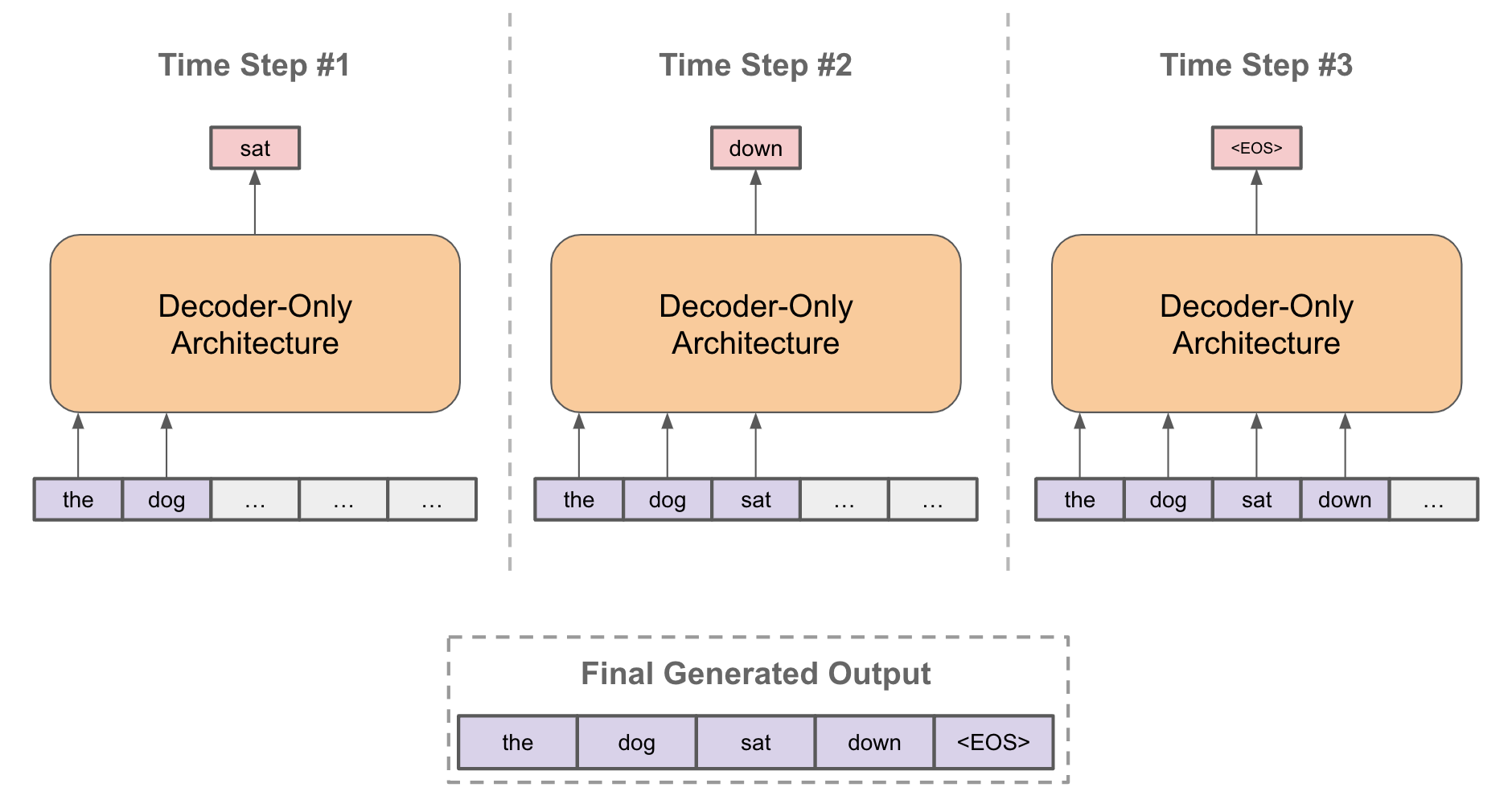
Masked self-attention is required for language modeling because we should not be able to look forward in the sentence while predicting the next token. Using masked self-attention yields an autoregressive architecture (i.e., meaning that the model’s output at time t is used as input at time t+1) that can continually predict the next token in a sequence; see below.
For tasks that do not require masked self-attention (e.g., sentence classification, tagging, etc.), however, we should remember that using bidirectional self-attention is really beneficial; see the link below for more details.
creating foundation models
Now that we have a basic understanding of language modeling and relevant architectures, we can understand the inspiration behind the GPT LMs, which begins with the following observations:
Unlabeled text corpora are largely abundant
Labeled data is scarce
For most deep learning systems, a lot of labeled data is needed to perform discriminative language understanding tasks. Current deep learning systems are narrow experts. The model is simply trained over a large, supervised dataset such that it learns to accurately perform a specific task; see below.

Though commonly used, this approach suffers a few major limitations:
Some domains do not have much labeled data
We have to train a new model for every task that we want to solve (and training deep learning models is expensive!)
foundation models. GPT and GPT-2 move away from the paradigm of narrow experts within deep learning. Rather than train a new model for every application, we can pre-train a single LM, then somehow adapt this model to solve numerous tasks. Generic models that are used to solve many tasks are referred to as foundation models.
This approach mitigates problems with data scarcity by pre-training over a large, diverse dataset. Additionally, these models can be reused or adapted to solve other tasks, allowing us to avoid constantly training new models. One approach for adapting a foundation model to a downstream task is to perform fine-tuning (i.e., more training) over a supervised dataset. More recently, however, the go-to approach is via zero or few-shot inference.
zero/few-shot inference via prompting. The GPT models receive text as input and produce text as output. We can exploit this generic input-output structure by providing inputs like the following:
“Translate this sentence to English:
<sentence> =>”“Summarize the following document:
<document> =>”.
These task-solving “prompts” enable zero-shot (i.e., without seeing examples of correct output) inference with LMs. Given these prompts, the most appropriate output from the LM should solve the task (e.g., translating to English or summarizing a document)! To perform few-shot inference, we can construct a similar prompt with examples of correct output provided at the start; see below.

Publications
We will now overview the details of GPT and GPT-2. Published by researchers at OpenAI, these models pioneered the use of generic LMs for solving downstream tasks. They laid the foundation for breakthrough advancements like GPT-3. The main differentiator between these models is simply the size of the underlying LM.
Improving Language Understanding by Generative Pre-Training (GPT) [1]
GPT is a general purpose language understanding model that is trained in two phases: pre-training and fine-tuning.

GPT uses a 12-layer, decoder-only transformer architecture that matches the original transformer decoder [6] (aside from using learnable positional embeddings); see the figure above. GPT first performs language model pre-training over the BooksCorpus dataset, then is separately fine-tuned (in a supervised manner) on a variety of discriminative language understanding tasks.
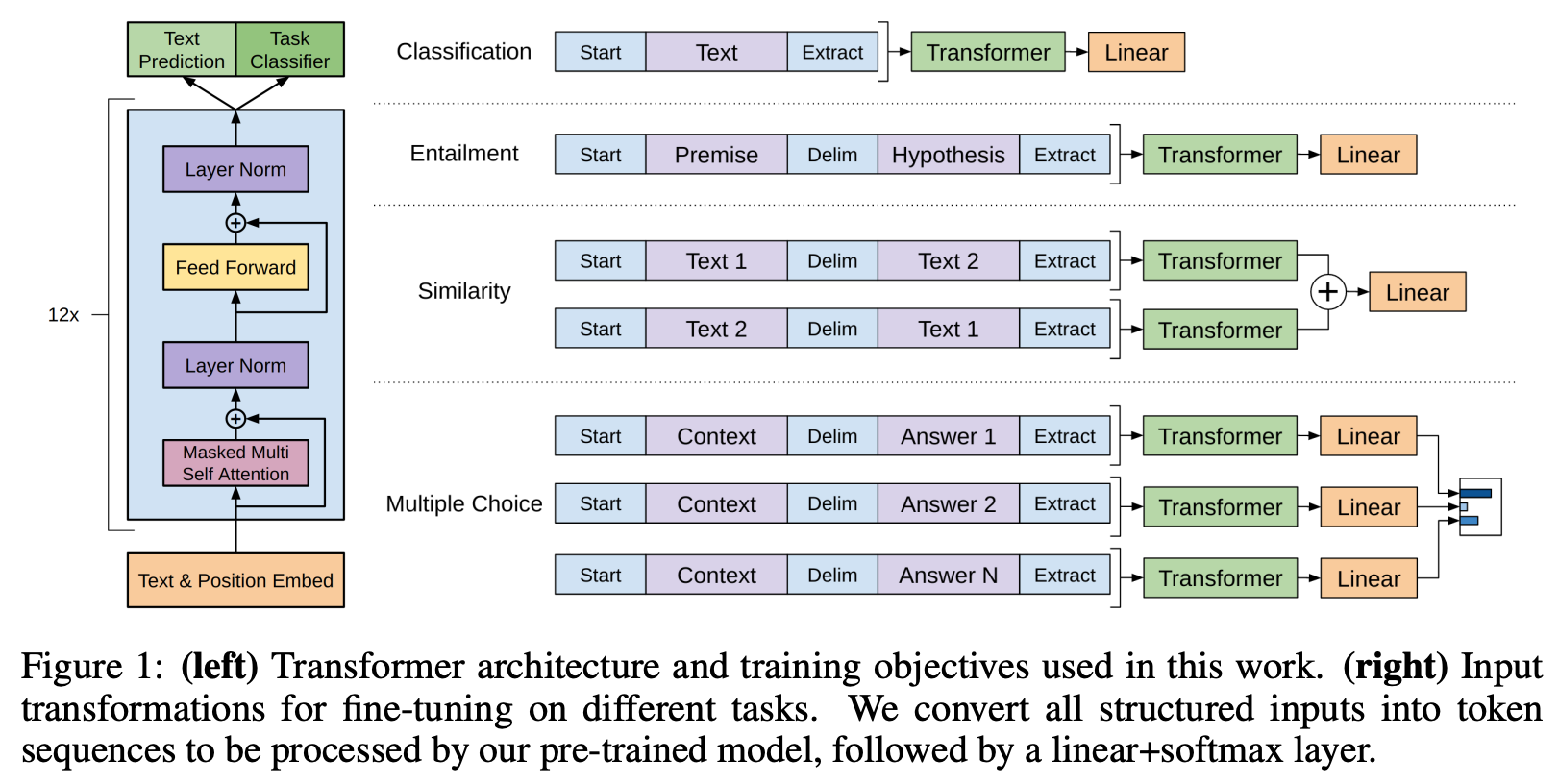
Instead of modifying GPT’s architecture to solve different tasks, we provide input in a task-specific structure, then pass the model’s output to a separate classification layer. For example, on entailment tasks, we concatenate the input sentences, separate them with a special delimiter, provide this input to GPT, then pass GPT’s output to a separate classification layer. Fine-tuning GPT with different supervised tasks is explained further in Section 3.3 of [1] and illustrated above.
GPT is evaluated on a wide variety of tasks listed above. The authors find that pre-training GPT on a corpus with long spans of contiguous text (as opposed to individual, shuffled sentences) is essential (this finding was also verified by more recent work [9]). Across experimental settings, we see that GPT achieves state-of-the-art performance on 9 of the 12 tasks and even consistently outperforms model ensembles; see below.
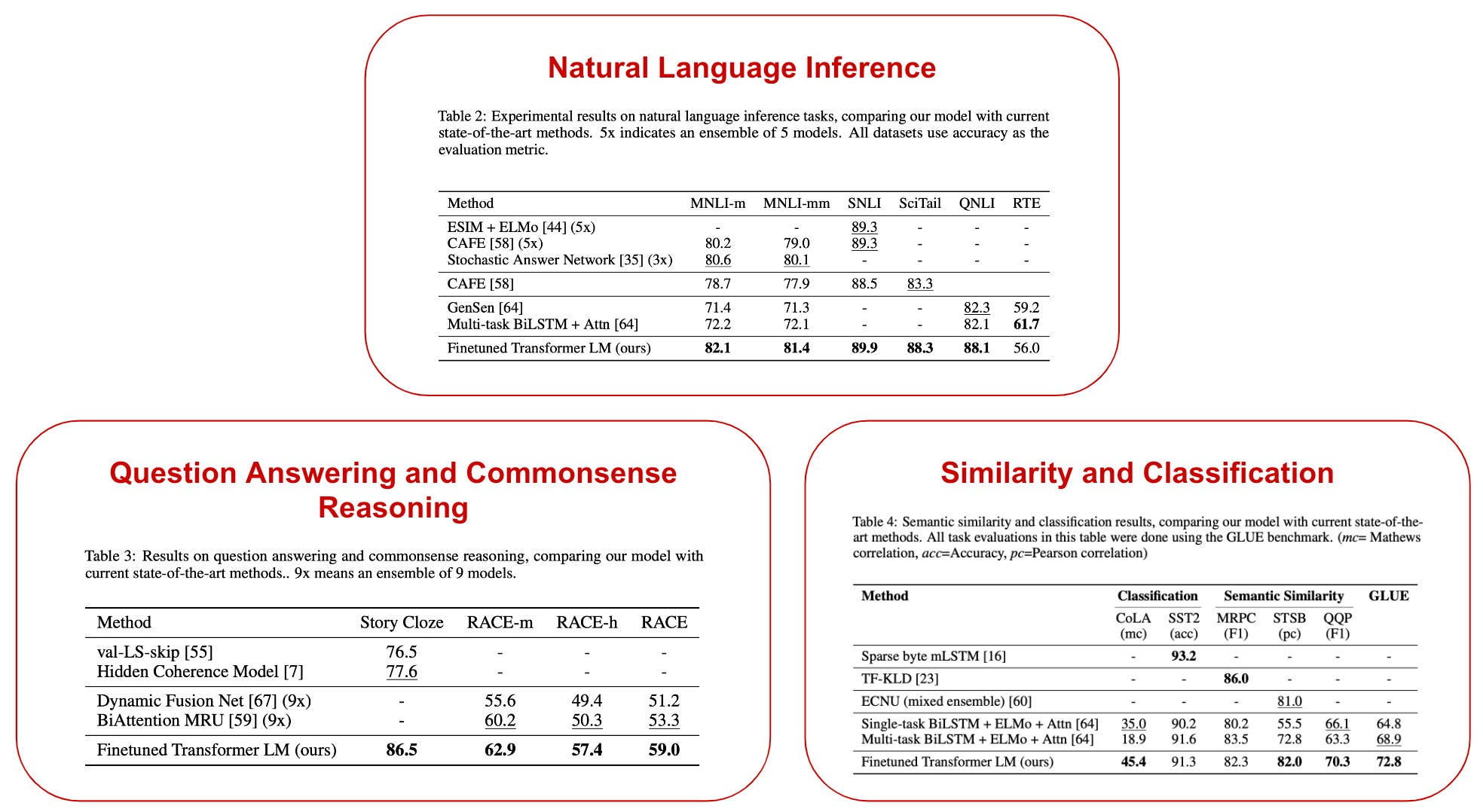
From these experiments, we learn that general purpose LMs understand linguistic concepts relatively well and are capable of learning complex patterns (e.g., long-term dependencies, linguistic ambiguity, etc.) within textual data. Without using any task-specific architectures or modifications, GPT outperforms numerous baselines by a large margin, including many specialized solutions for solving individual tasks.
Language Models are Unsupervised Multitask Learners (GPT-2) [2]
The proposal of GPT-2 [2] follows a similar pattern as its predecessor. The model is pre-trained using a language modeling objective, but it performs no fine-tuning, choosing to solve downstream tasks in a zero-shot manner instead. Put simply, GPT-2 performs multi-task learning by:
Pre-training a generic LM over raw textual data
Using textual “prompts” to perform zero-shot inference on a variety of tasks
Pre-training is performed over a custom WebText dataset that is constructed by scraping popular links from Reddit, and four different sizes of LMs are tested. The smallest model matches the size of GPT [1] and the largest model is GPT-2; see below.

The model architecture is identical to GPT, barring a few minor differences (e.g., different weight initialization, larger vocabulary, longer input sequence, etc.). Despite the size of these LMs, they are found to underfit the WebText dataset during pre-training, indicating that larger LMs would perform even better.
GPT-2 is evaluated on several tasks (i.e., language modeling, question answering, translation, etc.), where it achieves promising (but not always state-of-the-art) results. For example, in the table below we see that GPT-2 performs well on language modeling and reading comprehension tasks but falls far short of baselines for summarization and question answering.

Even though the performance isn’t great, we need to remember that GPT-2 performs no fine-tuning to solve any of these tasks. All of these results are achieved via zero-shot inference, which makes GPT’s competitive performance on certain tasks pretty impressive.
Interestingly, zero-shot performance consistently improves with the size of the underlying LM, indicating that increasing an LM’s size/capacity improves its ability to learn relevant features during pre-training; see below.

Pre-training and fine-tuning is an effective transfer learning paradigm, but GPT-2 shows us that easier, more general methods of transfer exist. Given that they are pre-trained over a sufficiently-large corpus, LMs seem to be capable of learning downstream tasks even without any architectural or parameter modifications. Although GPT-2’s performance is not impressive, the authors indicate that larger LMs will be much better.
“… a language model with sufficient capacity will begin to learn to infer and perform the tasks demonstrated in natural language sequences in order to better predict them, regardless of their method of procurement.” -from [2]
Takeaways
GPT and GPT-2 taught us a lot about deep learning. Though their effectiveness on downstream tasks was not incredibly impressive from an accuracy perspective, they provided a glimpse into the incredible potential of LMs as foundation models and laid the methodological foundation for the emergence of LLMs like GPT-3. The impact of these models is far-reaching, but I’ve tried to summarize some of the most useful takeaways and ideas from research on GPT and GPT-2 below.
language model pre-training is awesome. Transformers, due to their efficient utilization of compute, enable language model pre-training to be performed at a massive scale. The representations learned during this pre-training process allow pre-trained LMs to generalize well to solving other tasks. Put simply, LMs aren’t just good at language modeling – they can solve other tasks too!
size matters. As we see in the transition from GPT to GPT-2, increasing the size of the pre-trained LM increases the quality of the learned representations; e.g., GPT-2 far outperforms GPT in terms of zero/few-shot inference. This trend became more pronounced after the release of the (larger) GPT-3 model [7].
we should leverage foundation models. Most deep learning models are trained to accomplish a single, narrow task. In many cases, however, we can benefit from (i) pre-training a larger model via self-supervised learning on unlabeled data and (ii) adapting this model to solve many tasks. Such repurposing of large, foundation models is computationally efficient (i.e., computation is shared across many tasks) and not specific to LMs. We can train foundation models for domains like computer vision too [8]!
code and resources
For those interested in trying out applications with GPT-2, the code is publicly available! However, pre-training such a model is quite computationally expensive. A better approach would be to download a pre-trained language model and either fine-tune it or perform zero/few-shot inference (e.g., by using the demo below).
New to the newsletter?
Hello! I am Cameron R. Wolfe, a research scientist at Alegion and PhD student at Rice University. I study the empirical and theoretical foundations of deep learning. This is the Deep (Learning) Focus newsletter, where I pick a single, bi-weekly topic in deep learning research, provide an understanding of relevant background information, then overview a handful of popular papers on the topic. If you like this newsletter, please subscribe, share it with your friends, or follow me on twitter!
Bibliography
[1] Radford, Alec, et al. "Improving language understanding by generative pre-training." (2018).
[2] Radford, Alec, et al. "Language Models are Unsupervised Multitask Learners."
[3] Pennington, Jeffrey, Richard Socher, and Christopher D. Manning. "Glove: Global vectors for word representation." Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP). 2014.
[4] Conneau, Alexis, et al. "Supervised learning of universal sentence representations from natural language inference data." arXiv preprint arXiv:1705.02364 (2017).
[5] Howard, Jeremy, and Sebastian Ruder. "Universal language model fine-tuning for text classification." arXiv preprint arXiv:1801.06146 (2018).
[6] Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems 30 (2017).
[7] Brown, Tom, et al. "Language models are few-shot learners." Advances in neural information processing systems 33 (2020): 1877-1901.
[8] Yuan, Lu, et al. "Florence: A new foundation model for computer vision." arXiv preprint arXiv:2111.11432 (2021).
[9] Krishna, Kundan, et al. "Downstream Datasets Make Surprisingly Good Pretraining Corpora." arXiv preprint arXiv:2209.14389 (2022).