


Effortless Distributed Training of Ultra-Wide GCNs
An overview of GIST, a novel distributed training framework for large-scale GCNs.

In this post, I will overview a recently proposed distributed training framework for large-scale graph convolutional networks (GCNs), called graph independent subnetwork training (GIST) [1]. GIST massively accelerates the GCN training process for any architecture and can be used to enable training of large-scale models, which exceed the capacity of a single GPU. I will aim to cover the most pivotal aspects of GIST within this post, including relevant background information, a comprehensive description of the training methodology, and details regarding the experimental validation of GIST. A full, detailed manuscript was written to describe GIST and is available on Arxiv. Furthermore, the source code for all experiments performed with GIST is publicly available on GitHub.
Introduction
Machine learning and deep learning have been already popularized through their many applications to industrial and scientific problems (e.g., self-driving cars, recommendation systems, person tracking, etc.), but machine learning on graphs, which I will refer to as graphML for short, has just recently taken the spotlight within computer science and artificial intelligence research. Although many reasons for the popularization of graphML exist, a primary reason is the simple fact that not all data can be encoded in the Euclidean space. Graphs are a more intuitive data structure in numerous applications, such as social networking (i.e., nodes of the graph are people and edges represent social connections) or chemistry (i.e., nodes of the graph represent atoms and edges represent chemical bonds). As such, generalizing existing learning strategies on Euclidian data (e.g., convolutional neural networks, transformers, etc.) to work on graphs is a problem of great value.
Towards this goal, several (deep) learning techniques have been developed for graphs, the most popular of which is the graph convolutional network (GCN) [2]. The GCN implements a generalization of the convolution operation for graphs, inspired by a first-order approximation of spectral graph convolutions. Despite the popularity of the GCN and its widespread success in performing node and graph-level classification tasks, the model is notoriously inefficient and difficult to scale to large graphs. Such an issue catalyzed the development of node partitioning techniques, including both neighborhood sampling (e.g., LADIES and FastGCN) and graph partitioning (e.g., ClusterGCN and GraphSAGE), that divide large graphs into computationally-tractable components. Nonetheless, the data used within graphML research remains at a relatively small scale, and most GCN models are limited in size due to the problem of oversmoothing in deeper networks [3]. Such use of smaller data and models in graphML experimentation is in stark contrast to main stream deep learning research, where experimental scale is constantly expanding.
To bridge the gap in scale between deep learning and graphML, GIST aims to enable experiments with larger models and datasets. GIST, which can be used to train any GCN architecture and is compatible with existing node partitioning techniques, operates by decomposing a global GCN model into several, narrow sub-GCNs of equal depth by randomly partitioning the hidden feature space within the global model. These sub-GCNs are then distributed to separate GPUs and trained independently and in parallel for several iterations prior to having their updates aggregated into the full, global model. Then, a new group of sub-GCNs is created/distributed, and the same process is repeated until convergence. In cases of very large graphs, we adopt existing graph partitioning approaches to form mini-batches, which allows GIST to train GCN models on arbitrarily large graphs.
Put simply, GIST aims to provide a distributed training framework for large-scale GCN experiments with minimal wall-clock training time. Furthermore, because GIST trains sub-GCNs instead of ever training the global model directly, it can be used to train models with extremely large hidden layers that exceed the capacity of a single GPU (e.g., we use GIST to train a “ultra-wide” 32,768-dimensional GraphSAGE model on Amazon2M). It should be noted that we choose to focus on scaling model width, rather than depth, due to the fact that deep GCN models are known to suffer from oversmoothing [3].
What’s the GIST?
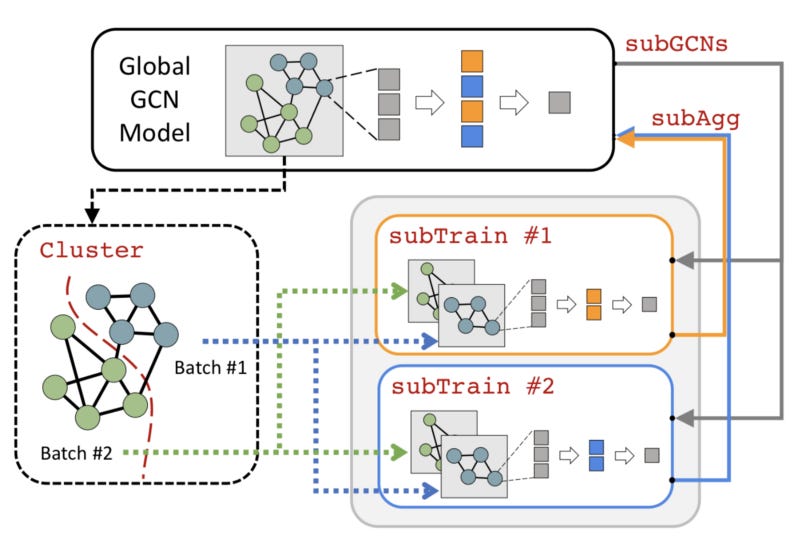
Here, we explain the general training methodology employed by GIST. This training methodology, which aims to enable fast-paced, large-scale GCN experimentation, is compatible within any GCN architecture or sampling methodology. We assume in our explanation that the reader has a general understanding of the GCN architecture. For a comprehensive overview of the GCN architecture, we recommend this article. A global view of the GIST training methodology is provided in Figure 1, and we further explain each component of this methodology within the following sections.
Creating Sub-GCNs

The first step in training a GCN model with GIST is partitioning the hidden dimensions of the global model to form multiple, narrow sub-GCNs of equal depth (i.e., sub-GCNs in Figure 1). The number of sub-GCNs, denoted as m, must be known prior to partitioning. Then, for each hidden layer of the global model, the indices of neurons within the layer are randomly partitioned into m disjoint groups of equal size, corresponding to different sub-GCNs. Once these partitions are constructed, a sub-GCN weight matrix at an arbitrary layer can be constructed by indexing the rows of the global weight matrix with the partition indices from the previous layer and columns of the global weight matrix with partition indices of the current layer. As such, this partitioning methodology creates smaller weight matrices for each sub-GCN that correspond to the random feature partition that has been selected.
The above methodology, depicted in Figure 2, is performed for all layers of the global GCN model, but the input and output dimensions are excluded from partitioning. The input dimension (i.e., d0 in Figure 2) is not partitioned because it would result in each sub-GCN having access only to a portion of the input vector for each node, which causes a drastic performance decrease with larger values of m. Similarly, the output dimension of the global model (i.e., d3 in Figure 2) is not partitioned so that each sub-GCN produces an output vector of the same size. As a result, no modification to the loss function is needed, and all sub-GCNs can be trained to minimize the same global loss function.
Once sub-GCNs are constructed, they are each sent to separate GPUs to be trained independently and in parallel. It should be noted that the full model is never communicated (i.e., only sub-GCNs are communicated between devices), which drastically improves the communication efficiency of distributed training with GIST. The process of sub-GCN partitioning is illustrated within the Figure 2, where different sub-GCN partitions are denoted with orange and blue colors. Recall that the input and output dimensions are not partitioned within GIST, which is shown in (b) of Figure 2.
Training Sub-GCNs
After sub-GCNs are constructed and sent to their respective devices, they are each trained independently and in parallel for a set number of iterations (i.e., subTrain in Figure 1), referred to as local iterations. When sub-GCNs have completed their local iterations, the parameter updates of each sub-GCN are aggregated into the global model, and a new group of sub-GCNs is created. This process repeats until convergence. As previously mentioned, sub-GCNs are trained to minimize the same global loss function. Additionally, each sub-GCN is trained over the same data (i.e., no non-iid partition of the data across devices is assumed).
To ensure the total amount of training is kept constant between models trained with GIST and using standard, single-GPU methodology, GCN models trained with GIST have the total number of training epochs split across sub-GCNs. For example, if a vanilla, baseline GCN model is trained for 10 epochs using a single GPU, then a comparable GCN model trained with GIST using two sub-GCNs would conduct 5 epochs of training for each sub-GCN. Because sub-GCNs are trained in parallel, such a reduction in the number of training epochs for each sub-GCN results in a large training acceleration.
If the training graph is small enough, sub-GCNs conduct full-batch training in parallel. However, in cases where the training graph is too large for full-batch training to be performed, a graph partitioning approach is employed to decompose the training graph into smaller, computationally-tractable sub-graphs as a pre-processing step (i.e., Cluster in Figure 1). These sub-graphs are then used as mini-batches during independent training iterations, which loosely reflects the training approach proposed by clusterGCN [4]. Although any partitioning approach can be used, GIST employs METIS due to its proven efficiency on large-scale graphs [5].
Aggregating Sub-GCNs
After sub-GCNs complete independent training, their parameters must be aggregated into the global model (i.e., subAgg in Figure 1) before another independent training round with new sub-GCNs may begin. Such aggregation is performed by simply copying the parameters of each sub-GCN into their corresponding locations within the global model. No collisions occur during this process due to the disjointness of the feature partition created within GIST. Interestingly, not all parameters are updated within each independent training round. For example, within (b) of Figure 2, only overlapping orange and blue blocks are actually partitioned to sub-GCNs, while other parameters are excluded from independent training. Nonetheless, if sufficient independent training rounds are conducted, all parameters within the global model should be updated multiple times, as each training round utilizes a new random feature partition.
Why is GIST useful?
At first glance, the GIST training methodology may seem somewhat complex, causing one to wonder why it should be used. In this section, I outline the benefits of GIST and why it leads to more efficient, large-scale experimentation on graphs.
Architecture-Agnostic Distributed Training
GIST is a distributed training methodology that can be used for any GCN architecture. In particular, GIST is used to train vanilla GCN, GraphSAGE, and graph attention network (GAT) architectures within the original manuscript, but GIST is not limited to these models. Therefore, it is a generic framework that can be applied to accelerate the training of any GCN model.
Compatibility with Sampling Methods
The feature partitioning strategy within GIST is orthogonal to the many node partitioning strategies that have been proposed for efficient GCN training. Therefore, any of these strategies can be easily combined with GIST for improved training efficiency. For example, graph partitioning is used to enable training of GCNs over larger graphs with GIST, and GIST is even used to train GraphSAGE models. Such experiments demonstrate the compatibility of GIST with existing approaches for graph and neighborhood sampling.
Ultra-Wide GCN training
GIST indirectly updates the global GCN model through the training of smaller sub-GCNs, which enables models with extremely large hidden dimensions (i.e., exceeding the capacity of a single GPU) to be trained. For example, when training a GCN model with GIST using 8 sub-GCNs, the model’s hidden dimension can be made roughly 8X larger in comparison to models at the capacity limit of a single GPU. Such a property enables the training of “ultra-wide” GCN models with GIST, as is demonstrated in experiments with GIST.
Improved Model Complexity
GIST reduces both communication and computational complexity of distributed GCN training significantly, resulting in a drastic acceleration of wall-clock training time. Such a complexity reduction is created by the fact that only sub-GCNs, which are significantly smaller than the global model, are communicated and trained by GIST. More precise expressions for the complexity reductions provided by GIST are available within the originaln manuscript.
How does GIST perform in practice?
Within this section, I overview the experiments performed using GIST, which validate its ability to train GCN models to high performance with significantly reduced wall-clock time. Experiments are performed over numerous datasets, including Cora, Citeseer, Pubmed, OGBN-Arxiv, Reddit, and Amazon2M. However, I focus upon experiments with Reddit and Amazon2M within this post, as these datasets are much larger and more relevant to practical graphML applications. The smaller datasets are mostly used as design/ablation experiments for the GIST methodology, and more details are available within the manuscript.
Reddit Dataset

Experiments with GIST on the Reddit dataset are performed with 256-dimensional GraphSAGE and GAT models with two to four layers. Models are trained with GIST using multiple different numbers of sub-GCNs, where each sub-GCN is assumed to be distributed to a separate GPU (i.e., 8 sub-GCN experiments utilize 8 GPUs in total). 80 epochs of total training are performed using the Adam optimizer and no weight decay, and the number of local iterations is set to 500. The training graph is partitioned into 15,000 sub-graphs during training. Baseline models are trained using standard, single-GPU methodology, and all other experimental details are held constant. As can be seen in Figure 3, all models trained with GIST achieve performance that matches or exceeds that of models trained with standard, single-GPU methodology. Additionally, the training time of GIST is significantly reduced in comparison to standard, single-GPU training.
Amazon2M Dataset

Experiments with GIST on the Amazon2M dataset are performed using GraphSAGE models with hidden dimensions of 400 and 4096 (i.e., narrow and wide models) and different numbers of layers. Again, models are trained with GIST using multiple different numbers of sub-GCNs and the training graph is decomposed into 15,000 partitions. Baseline experiments are performed using standard, single-GPU training methodology. Training is conducted using the Adam optimizer with no weight decay for 400 total epochs, and the number of local iterations is set to 5,000. As can be seen in Figure 4, models trained with GIST complete training significantly faster in comparison to baseline models trained with standard, single-GPU methodology. Furthermore, models trained with GIST perform comparably to those trained with standard methodology in all cases.
Ultra-Wide GCNs
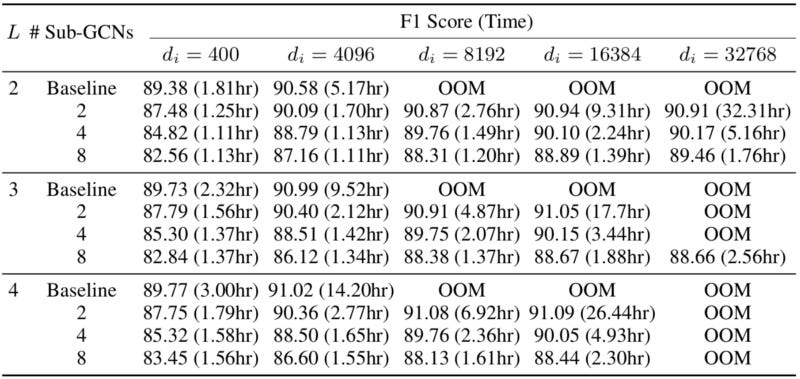
As previously mentioned, GIST can be used to train incredibly-wide GCN models due to the fact that the global model is indirectly updated through the independent training of sub-GCNs. To demonstrate this capability, GraphSAGE models with increasingly-large hidden dimensions are trained over the Amazon2M dataset. As is shown in Figure 5, GIST can be used to train GraphSAGE models with hidden dimensions as large as 32,768 to high-performance on the Amazon2M dataset with relatively minimal training time. Single-GPU training methodologies reach an out-of-memory error in these cases (even in GCN models that are significantly smaller), thus demonstrating that GIST can be used to train models that far-exceed the capacity of a single GPU. Furthermore, the wall-clock training time of models trained with only a single GPU becomes quite prohibitive in comparison to models trained with GIST, thus highlighting its ability to accelerate large-scale GCN experiments. As demonstrated through these experiments, GIST enables GCN experimentation at scales that were previously not feasible.
Conclusion
In this blog post, I outlined GIST, a novel distributed training methodology for large GCN models. GIST operates by partitioning a global GCN model into several, narrow sub-GCNs that are distributed across separate GPUs and trained independently and in parallel before having their parameters aggregated into the global model. GIST can be used to train any GCN architecture, is compatible with existing sampling methodologies, and can yield significant accelerations in training time without decreasing model performance. Furthermore, GIST is capable of enabling training of incredibly-wide GCN models to state-of-the-art performance, such as a 32,768-dimensional GraphSAGE model on the Amazon2M dataset.
I truly appreciate your interest in this blog post. If you have any comments or questions, feel free to contact me or leave a comment (contact information is available on my website). GIST was developed as part of the independent subnetwork training (IST) initiative within my research lab at Rice University. More information about related projects can be found here.
Citations
[1] https://arxiv.org/abs/2102.10424
[2] https://arxiv.org/abs/1609.02907
[3] https://arxiv.org/abs/1801.07606
[4] https://arxiv.org/abs/1905.07953
[5] http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.106.4101