
StreamingLLM, QA-LoRA, GPT-4V, LLaVA, Reversal Curse and More
Notable advances in LLM research prior to the week of October 10th, 2023...


Within this overview, we will take a look at a variety of recent publications on the topic of large language models (LLMs), including the following papers:
Efficient Streaming Language Models with Attention Sinks [1]
QA-LoRA: Quantization-Aware Low-Rank Adaptation of Large Language Models [4]
Physics of Language Models: Part 3.1 (Knowledge Storage and Extraction) [9] and Part 3.2 (Knowledge Manipulation) [10]
The papers above address important/open problems within AI research, such as i) making LLMs less computationally burdensome, ii) enabling longer sequences of text to be generated, iii) incorporating visual (image) inputs, and iv) better understanding how (transformer-based) LLMs process and store knowledge. These problems are incredibly important from both an application and research perspective, so let’s get into the details and implications for AI research.
Efficient Streaming Language Models with Attention Sinks [1]

This paper stirred up a lot of discussion on Twitter/X last week after its publication, as it attempts to solve existing limitations that LLMs have with decoding very long sequences of text. When generating text with an LLM, we typically employ a KV cache to speed up the inference process. This is one of the most basic methods of improving inference speed, but it also consumes a lot of memory, especially when the sequence of generated text is long. Furthermore, LLMs fail to generalize to input sequence lengths longer than those seen during training—they are typically limited to a fixed context length. StreamingLLM [1] aims to solve these problems associated with generating long sequences of text.
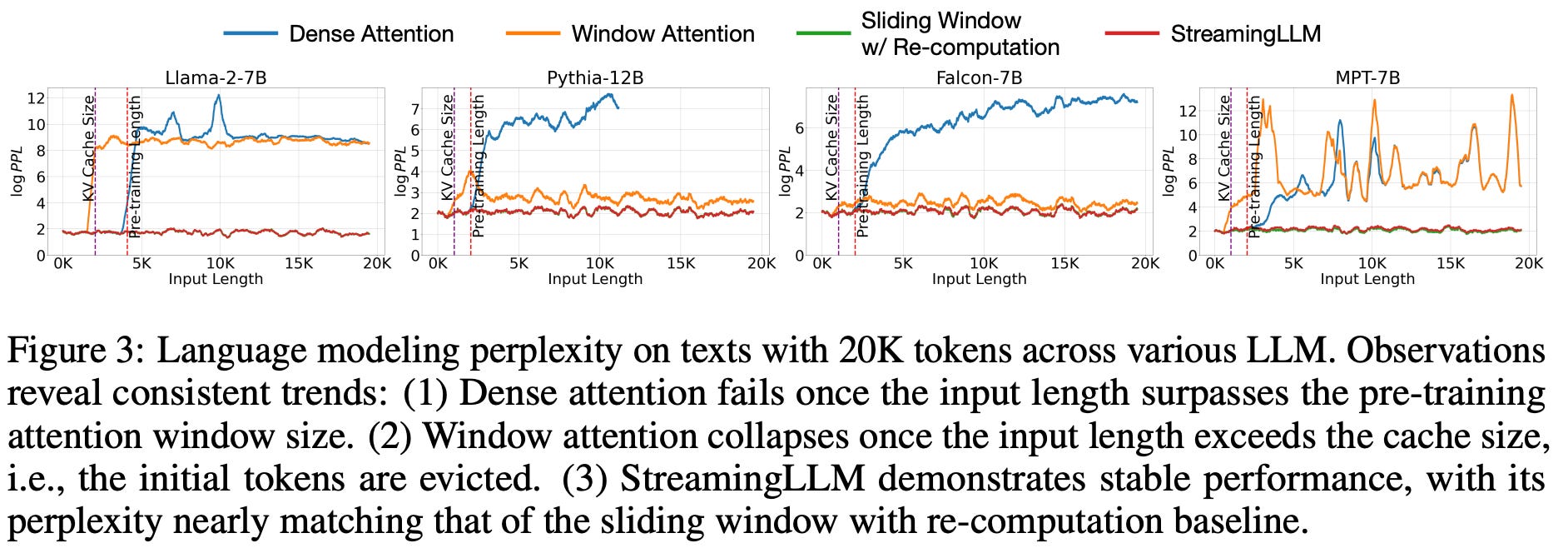
An intuitive baseline. One previously-proposed approach for dealing with the problems outlined above is to just only consider a window of prior tokens within the attention computation. This way, we can evict tokens that go beyond a certain window length L and simply continue to generate text based on a sliding window of tokens within the past. However, this “window attention” approach has one major problem—it drastically deteriorates performance once we start to generate enough text. See the experiments above for examples of this behavior.
“It is evident that perplexity spikes when the text length surpasses the cache size, led by the exclusion of initial tokens. This suggests that the initial tokens, regardless of their distance from the tokens being predicted, are crucial for maintaining the stability of LLMs.” - from [1]
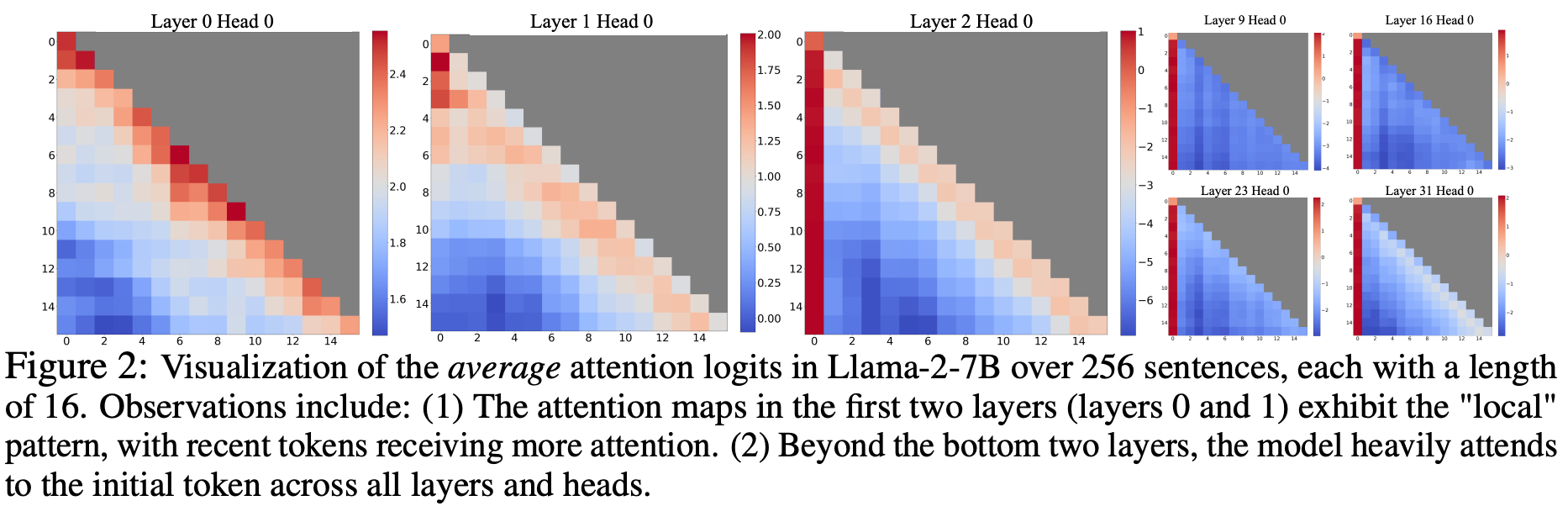
Attention sinks. By examining input lengths at which perplexity begins to spike, authors in [1] realize that LLM performance with window attention deteriorates when initial input tokens are evicted from the cache window. This means that, no matter how long the sequence of generated text, including the initial tokens within the attention window is important. This finding was confirmed after the attention maps of different layers in the LLM were examined, where authors observe that all layers (aside from initial few layers) focus their attention heavily on the tokens at the beginning of the input sequence.
“Due to the sequential nature of autoregressive language modeling, initial tokens are visible to all subsequent tokens, while later tokens are only visible to a limited set of subsequent tokens. As a result, initial tokens are more easily trained to serve as attention sinks, capturing unnecessary attention.” - from [1]
To explain this behavior, authors in [1] introduce the concept of an “attention sink”, where an LLM assigns unnecessarily-high attention values to a certain set of tokens. Why does this happen? Put simply, the softmax function prevents all tokens within the attention mechanism from being assigned zero probability, so the model is forced to aggregate information from all token values in each of its attention heads, which causes unnecessary attention values to be “dumped” into certain tokens. In [1], authors find that multiple initial tokens within the LLM’s input sequence tend to serve as an attention sink; see below. Initial tokens seem to make great attention sinks, as they are visible to all subsequence tokens.
StreamingLLM. The approach proposed in [1] improves the ability of LLMs to generate long sequences of text by combining a rolling KV cache with the idea of an attention sink. In other words, the attention window used for generating text in [1] includes a rolling window of previous tokens, as well as the four initial tokens within the model’s input sequence; see below. In other words, initial tokens are always considered by the model when generating text of any length.

This approach requires no fine-tuning and can be incorporated into any existing (GPT-style) language model that uses a relative positional encoding scheme (e.g., RoPE). Experimental results with this approach are shown below, where we see that StreamingLLM maintains impressive language modeling performance and drastically decreases decoding latency with a stable/fixed memory footprint.

Dedicated sink tokens. Authors in [1] note that the observed pattern of having several tokens acting as attention sinks at the beginning of the input sequence is due to the lack of a unified “start” token. Most LLMs are trained over textual sequences directly sampled from the pretraining corpus, leading the initial token in each training sequence to be random. By always prepending a unified starting token—called the sink token—at the beginning of each sequence during pretraining, the model learns to use this particular token as an attention sink. As such, authors in [1] recommend that LLMs in the future be pretrained with a dedicated sink token to optimize streaming deployment; see above.
Impact. A lot of people on Twitter/X seemed to think that StreamingLLM increased the context window of language models significantly, as the paper claims (and achieves) generation of outputs as long as 4M tokens. However, it is important to notice that StreamingLLM does not compute dense attention over all of these tokens. Rather, it enables generation of very long sequences of text by performing attention over only initial (sink) tokens and a window of recent tokens. As such, it does not fundamentally expand the context window. Nonetheless, it is a great practical tool, as streaming long outputs from an LLM can be applied to a variety of different applications. Check out the code for StreamingLLM below.
GPT-4V(ision) system card [2]
“Incorporating additional modalities (such as image inputs) into large language models (LLMs) is viewed by some as a key frontier in artificial intelligence research and development. Multimodal LLMs offer the possibility of expanding the impact of language-only systems with novel interfaces and capabilities, enabling them to solve new tasks and provide novel experiences for their users.” - from [2]
If you haven’t heard of GPT-4V yet, you might be living under a rock. At a high level, GPT-4V is the (long-anticipated) multi-modal extension of GPT-4 that enables the model to process both textual and visual (i.e., images) input from the user. Currently, GPT-4V is available within ChatGPT Plus for select users1. The system card for GPT-4V, which was released alongside the model, does not reveal many technical details. Rather, it focuses on evaluations and mitigation efforts taken to ensure that ingesting visual input within GPT-4 is safe.
GPT-4V training. GPT-4V was trained in 2022—in fact, the original release of GPT-4 mentioned multi-modal capabilities that were not available yet—and early access to the model started in March of this year. Notably, the training process of GPT-4 and GPT-4V are the same, as GPT-4V is based upon GPT-4. Both models undergo the standard LLM training pipeline of pretraining and alignment (or finetuning) via reinforcement learning from human feedback (RLHF); see below.

Beta usage. The multi-modality of GPT-4V provides a ton of extra functionality, but it is also a risk surface—adversarial users can leverage this new input modality to get the model to demonstrate harmful behavior. OpenAI performed an extensive beta period to identify and mitigate risks associated with the model. In particular, two beta periods were organized for GPT-4V that served distinct purposes.
First, OpenAI collaborated with Be My Eyes to develop a GPT-4V-based tool for describing smart phone images to blind and low-vision users. In this application, GPT-4V was found to achieve reduced levels of hallucinations and drastically improve the quality of optical character recognition (OCR). Users of GPT-4V requested development of features related to analyzing and describing the faces/expression of others, which would help with better understanding social interactions. Despite the utility of GPT-4V, users were still recommended against relying upon GPT-4V for critical use cases (e.g., those related to safety or health).
GPT-4V was also released for early access to a small number of developers. This beta period was used to gather examples of queries that might come from users of the model (e.g., 20% of total queries requested explanations of images). As a result, OpenAI was able to better understand model usage and develop benchmarks for testing and mitigating issues that may occur with the general release of GPT-4V.

Launching GPT-4V. Developing the version of GPT-4V that was ultimately launched involved an extensive mitigation process of i) identifying failure cases in which the model produces an undesirable output (i.e., red teaming) and ii) further finetuning the model (via RLHF) to eliminate this harmful behavior. This iterative process drastically improves model quality; see above. Additionally, these improvements to GPT-4V can be augmented with an external refusal system (i.e., a module that detects when the model should refuse to answer a prompt), which further eliminates2 undesirable responses to harmful prompts; see below.

However, GPT-4V still has limitations that should be recognized. Notably, the model may lack (important) social context that can lead to harmful generations, still has simple biases (e.g., order of images in the prompt) that can impact its output, may perform unreliably in complex domains (e.g., science or medicine), and has the potential to generate harmful or incorrect instructions; see below.

Put simply, GPT-4V has limitations, but extensive effort was (successfully) invested into mitigating the worst of these limitations prior to its release.
Open-source version. Notably, GPT-4V is a closed source model that can only be used via OpenAI offerings. Luckily, however, the open-source AI research community moves quickly! Open-source variants of GPT-4V have already been proposed that can execute dialogue with both textual and visual inputs. One notable example is LLaVA, which combines the Vicuna LLM with a vision encoder to create an open-source, multi-modal language model.
Cool uses of GPT-4V. Upon the model’s release, we saw a variety of different interesting use cases for GPT-4V. A few of my favorites are listed below:
Generating code from Figma [link]
The Dawn of LMMs: Preliminary Explorations with GPT-4V(ision) [link]
This is an entire paper that explores use cases for GPT-4V, which makes it a great resources for learning about the model’s capabilities! 'Notably, this entire paper was published ~4 days after the GPT-4V model release, which is a great demonstration of the insane pace of AI research.
Understanding schematics of an Arduino design [link]
Picture of groceries to a grocery list [link]
Converting screenshots and sketches to code [link]
We have already seen tons of interesting use cases with GPT-4V, which demonstrates the massive utility of multi-modal LLMs. In the future, we’ll probably see more emphasis on multi-modal capabilities in this space, and the capabilities of these models to process visual information will only improve.
QA-LoRA: Quantization-Aware Low-Rank Adaptation of Large Language Models [4]
To understand QA-LoRA, we need to briefly overview the idea of LoRA, why it is important, and how it has been used in recent research. LoRA is one of the most widely used forms of parameter-efficient fine-tuning for LLMs, so research on this topic tends to have a lot of utility for AI practitioners.

Some background. Low rank adaptation (LoRA) [7] for LLMs is a parameter-efficient finetuning (PEFT) technique that allows us to finetune a pretrained LLM with minimal compute resources. To do this, we i) start with a pretrained LLM, ii) freeze (i.e., do not train) all of its weights, iii) inject trainable rank decomposition matrices3 (see above) into each layer of the transformer, and iv) only train the extra, injected layers. With this approach, the forward pass of each layer in the model will be formulated as shown below, where W0 is the original weight matrix for the layer and AB is the added rank decomposition matrix.

Compared to normal adapter layers, LoRA modules provide similar reductions in memory and computational complexity, as well as several extra benefits:
We can easily control/modify the number of trainable parameters—even nearing the point of full pretraining—by changing the sizes of
BandA.This does not change inference time at all, as we can just compute
W0 + BAdirectly and use this weight matrix when performing inference.We can recover the original weight matrix
W0if we knowAB, which in turn allows us to easily switch between several different LoRA models.
“Compared to GPT-3 175B fine-tuned with Adam, LoRA can reduce the number of trainable parameters by 10,000 times and the GPU memory requirement by 3 times.” - from [7]
Additionally, recent research has introduced variants of LoRA that further improve memory efficiency. For example, QLoRA [8] explores a quantized version of LoRA that further reduces memory overhead, allowing LLMs as large as 65B parameters to be finetuned on a single (48 Gb) GPU. For a practical (and more in-depth) overview of LoRA and related techniques, check out the post linked below.

What is QA-LoRA? The two major areas of research focused upon alleviating the computational burden (i.e., compute and memory overhead) of LLMs are:
PEFT: finetune pretrained LLMs with a small number of trainable parameters.
Quantization: convert trained weights of an LLM into low-bit representations.
The idea behind QA-LoRA [4] is to integrate these two ideas together in a simple and performant manner. Although prior research has attempted to perform post-training quantization (i.e., this means we quantize the weights after training and before inference) with PEFT, such an approach produces unsatisfying accuracy, especially at extreme quantization levels (e.g., 4-bits); see below.

Unlike LoRA and QLoRA, QA-LoRA improves both training and inference efficiency by introducing a group-wise quantization scheme that separately quantizes different groups of weights in the model. The resulting technique performs efficient finetuning with quantized weights according to this scheme and has no need for post-training quantization—which typically deteriorates accuracy—prior to performing inference; see below.
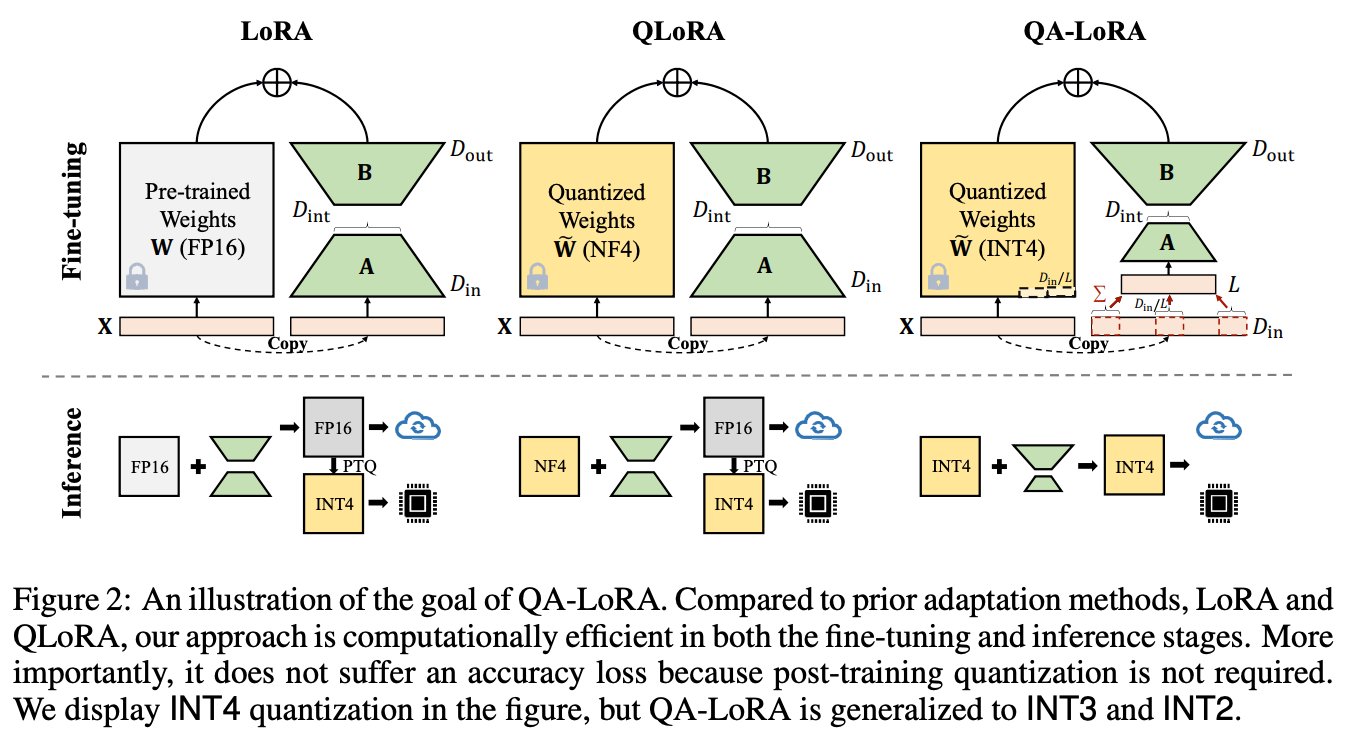
Despite its benefits, QA-LoRA is actually pretty easy to implement. An example implementation (in PyTorch-style pseudocode) is given in the figure below.

Experimental results. Overall, QA-LoRA’s quantization-aware training scheme achieves performance that is comparable to vanilla LoRA while matching the efficiency benefits of quantized techniques like QLoRA. As such, it is a practical approach that combines the efficiency benefits of both quantization and PEFT.
“QA-LoRA consistently outperforms QLoRA with PTQ on top of LLMs of different scales (the advantage becomes more significant when the quantization bit width is lower) and is on par with QLoRA without PTQ. Note that during inference, QA-LoRA has exactly the same complexity as QLoRA with PTQ and is much more efficient than QLoRA without PTQ.” - from [4]
Physics of Language Models: Part 3.1 (Knowledge Storage and Extraction) [9] and Part 3.2 (Knowledge Manipulation) [10]

The reversal curse [5] for LLMs can characterized by the following question: Does a language model trained on examples of the form “A <—> B” generalize to capturing the relationship “B <—> A”? For example, if a language model is trained on the sentence “George Washington was the first United States President”, can it easily answer the question “Who was the first United States Predident”? The answer—as explored in [5]—is no. Current LLMs struggle to capture relationships of this form. In fact, finetuning LLMs (e.g., GPT-3 or LLaMA) to test this ability yields a generalization accuracy of 0%—language models are terrible at solving this task!
Storing and extracting knowledge. Providing further analysis in a similar vein to the reversal curse, a recent line of papers studies the knowledge storage, extraction, and manipulation properties of language models. Currently, we know that language models contain extensive knowledge about the world that can be extracted via simple prompting or question answering. However, it is unclear whether these question answering abilities come from direct exposure to similar (or the exact same) data during pretraining or if the language model is actually extracting information from the data on which it is trained. To answer this question, authors of [9] perform an in-depth analysis of how language models memorize knowledge during training and extract it during inference.
Notably, memorizing knowledge does not necessarily mean that the language model will be capable of extracting or manipulating this knowledge during inference. In other words, there is a distinct difference between memory and knowledge. Using synthetically generated biographical data (real data that is formatted properly and cleaned with LLaMA-2), authors in [9] set out to answer the question posed below.
“After training a language model on the biography dataset, can the model be finetuned to extract the knowledge to answer questions like “Where is the birth city of [name ]” or “What did [name ] study?”, and if so, how does the model achieve so?” - from [9]
Interestingly, we see in [9] that language models cannot be finetuned to extract relevant knowledge. Put simply, this reveals that finetuning cannot recover from knowledge being stored improperly during pretraining. However, this problem can be solved by adding further data augmentation to the pretraining process. These findings are depicted in the figure below (from the author’s tweet).

This analysis has links to a variety of other LLM papers. Most notably, we have seen in prior work that LLMs learn all of their knowledge in pretraining, while alignment/finetuning serves to modify the manner in which this information is surfaced. In [9], we see further support for this claim, as finetuning can only be used to uncover information that is properly stored during pretraining.
“A language model cannot efficiently manipulate knowledge from pre-training data, even when such knowledge is perfectly stored and fully extractable in the models, and despite adequate instruct fine-tuning.” - from [10]"
Manipulating knowledge. Going further, analysis in [10] (performed by the same authors and released right after [9]!) expands upon work in [9] by studying the capabilities of language models to manipulate knowledge. Put simply, we learn from [9] about the ability of LLMs to store knowledge, but this doesn’t tell us anything about how this knowledge can be leveraged to perform reasoning. In particular, authors study four different forms of knowledge manipulation with LLMs:
Retrieval: “What is person A’s attribute X?”
Classification: “Is A’s attribute X even or odd?”
Comparison: “Is A greater than B in attribute X?”
Inverse Search: “Which person’s attribute X equals T?”
We learn in [10] that pretrained LLMs are good at retrieval but struggle with classification and comparison, unless chain of thought prompting is used. These models also struggle with inverse search in all cases. Again, these problems are studied using a synthetic dataset that enables fine-grained control and analysis of an LLM’s ability to store and manipulate knowledge. However, the high-level takeaway from [10] is that LLMs struggle with knowledge manipulation (beyond basic tasks like retrieval), even with properly-stored information and relevant finetuning. These results are summarized in the figure below (from the author’s tweet).

The findings from [9] and [10] give us more insight into how knowledge is stored and used in an LLM. Put simply, LLMs seems to learn all of their knowledge during pretraining. However, LLMs should not be used as a knowledge database, and they struggle with complex knowledge manipulation. Going further, tasks that require complex knowledge manipulation can be distilled into simpler (retrieval-style) tasks via chain of thought prompting, which breaks a larger problem into a multi-step process of smaller/simpler components.
Honorable Mentions
Although we only summarized a few papers with the above overview, there are tons of awesome AI research papers being published every week. Some notable papers that I came across recently are listed below:
Large Language Models are Effective Text Rankers with Pairwise Ranking Prompting [3]: studies pairwise ranking of textual documents with LLMs for search and information retrieval applications, finding that open-source LLMs can achieve state-of-the-art ranking performance.
GrowLength: Accelerating LLMs Pretraining by Progressively Growing Training Length [11]: studies progressively increasing the length of textual sequences used during training, finding that models with longer sequence lengths can be trained more efficiently with this approach (MPT does this!).
Mistral-7B: this is another open-source (Apache 2.0 license) LLM that was released by Mistral (a high-profile AI startup). The model caused a lot of Twitter/X discussion, and it seems like Mistral will be releasing more/better models in the (near) future.
Takeaways
We have seen a variety of different papers within this overview, but there are common patterns among each of these research topics. We can distill the major findings from this research into a few important takeaways:
Current LLM applications require large context lengths and the ability to generate long sequences. StreamingLLM [1] is a practical trick for streaming long output sequences efficiently with minimal performance degradation.
Although most LLMs until now have primarily leveraged a text-only interface, we are seeing a push towards multi-modal LLMs (e.g., GPT-4V [2]).
LLMs have a large computational overhead, but LoRA-based techniques allow practitioners to finetune and use LLMs with minimal compute requirements. QA-LoRA [4] is another step towards democratizing the ability to train and manipulate LLMs with modest resources.
LLMs memorize and extract information relatively well (assuming that such information is properly stored during pretraining), but they struggle with tasks that require extracting and manipulating relevant information [9, 10].
At a high level, recent research is pushing to understand how these models operate more deeply (i.e., what makes them so effective), as well as to make it easier and more efficient to train and use them in practical applications.
New to the newsletter?
Hi! I’m Cameron R. Wolfe, deep learning Ph.D. and Director of AI at Rebuy. This is the Deep (Learning) Focus newsletter, where I help readers understand AI research via overviews of relevant topics from the ground up. If you like the newsletter, please subscribe, share it, or follow me on Medium, X, and LinkedIn!
Bibliography
[1] Xiao, G., Tian, Y., Chen, B., Han, S., and Lewis, M., “Efficient Streaming Language Models with Attention Sinks”, arXiv e-prints, 2023.
[2] OpenAI et al., “GPT-4V(ision) System Card”, 2023.
[3] Qin, Zhen, et al. "Large language models are effective text rankers with pairwise ranking prompting." arXiv preprint arXiv:2306.17563 (2023).
[4] Xu, Yuhui, et al. "QA-LoRA: Quantization-Aware Low-Rank Adaptation of Large Language Models." arXiv preprint arXiv:2309.14717 (2023).
[5] Berglund, Lukas, et al. "The Reversal Curse: LLMs trained on" A is B" fail to learn" B is A"." arXiv preprint arXiv:2309.12288 (2023).
[6] Ouyang, Long, et al. "Training language models to follow instructions with human feedback." Advances in Neural Information Processing Systems 35 (2022): 27730-27744.
[7] Hu, Edward J., et al. "Lora: Low-rank adaptation of large language models." arXiv preprint arXiv:2106.09685 (2021).
[8] Dettmers, Tim, et al. "Qlora: Efficient finetuning of quantized llms." arXiv preprint arXiv:2305.14314 (2023).
[9] Allen-Zhu, Zeyuan et al. ”Physics of Language Models: Part 3.1, Knowledge Storage and Extraction
”, arXiv preprint arXiv:2309.14316 (2023).
[10] Allen-Zhu, Zeyuan et al. ”Physics of Language Models: Part 3.2, Knowledge Manipulation”, arXiv preprint arXiv:2309.14402 (2023).
[11] Jin, Hongye et al. “GrowLength: Accelerating LLMs Pretraining by Progressively Growing Training Length”, arXiv preprint arXiv:2310.00576 (2023).
ChatGPT Plus requires a paid ($20/month) subscription.
Notably, the OpenAI team actually achieves a refusal rate of 100% for the adversarial prompts present within their internal benchmark.
The term “rank decomposition matrix” might sound super complicated, but the idea is simple—we just parameterize our new weight matrix as a sum of the original weight matrix and a low-rank matrix. In particular, we parameterize this as W0 + BA, where W0 is the original weight matrix (size d x n) and BA is a product of lower rank weight matrices (sizes d x k and k x n, respectively).
trivial, but OCR has a typo—“optimal”
excellent write ups. i very much enjoy this style of post, as the field is expanding rapidly so breadth is necessary for good ideation.
how much do you find you learn when you write one of these up?